AI、IoTに関連したビジネスにおける特許戦略
第1回 AIビジネスと特許戦略
知的財産権・エンタメ
シリーズ一覧全2件
目次
AI、IoTに関連したビジネスにおける特許戦略
現在は、AIおよびIoT等の新たな技術の発展により、第4次産業革命の時代を迎えたといわれています。センシング技術の発達を背景としたIoT関連発明を製品化することで、職場や家庭等から多量のデータを収集し、AIにより分析し、その結果を現場へフィードバックするという一連の流れにより、新たな価値が創られることが期待されています。このように、多量のデータを取り扱う新技術であるという意味において共通するAIとIoTですが、実は、採りうる特許戦略は全く逆の方向を向いているのではないかと思います。
端的に言うと、AIに関連するビジネスはクローズ戦略、IoTに関連するビジネスはオープン戦略に馴染みやすいと言えます。その理由について解説していきましょう。
本稿では、2回にわたり、AIおよびIoTのそれぞれについて、その現状を概観したうえで、企業が採るべきまたは採りうる特許戦略を検討したいと思います。
AIビジネスと特許戦略
AIビジネスは黎明期にあり、その法的問題点に関する議論の蓄積は未だ十分ではありません。特許戦略は、特許法の枠内で完結するものではなく、そもそも、AIビジネスの分野で、何が法的問題の対象となりうるか、また、それに対して、どのような法的保護が考えうるかを俯瞰したうえで、今後、採りうるまたは採るべき戦略を検討していくことが重要です。
AIとは何か
まず、そもそも、AIとは何でしょうか。AIは「Artificial Intelligence」の略称であり、日本語では「人工知能」と訳されます。「知能」という言葉を見ると、アニメや映画に出てくるような、感情を持った、それこそ人間と見紛うレベルの高度な自律的判断能力(知性)を持ったロボットをイメージされる方も多いでしょう(このような意味でのAIを「汎用型AI」または「強いAI」と呼ぶこともあります)。
しかし、残念ながら、そのような非常に高度なレベルのAIが誕生するのは当分先の話です。現在、話題となっているAIは、それよりも少しレベルが下がった、人ができることを機械に行わせる、という意味でのいわば、人の「知的作業代替ツール」としてのAIです(このような意味でのAIを「特化型AI」または「弱いAI」と呼ぶこともあります)。

そのため、現状、AIそのものの権利または侵害主体性は問題とされておらず、あくまでも、人(場合によっては法人)が法的問題の中心であることには注意が必要です。
AIの仕組み
コンピュータのプログラムは、大まかに捉えれば、ある問題(入力)に対して、処理(モデル適用)を行い、回答を出す(出力)というステップで、問題を解決します。このレベルでは、AIと従来のアルゴリズムとの間に大きな違いはありません。違いがあるのは、従来のアルゴリズムでは、人があらかじめ適用すべきモデル等の決定を行う必要があったのに対して、AIでは、AI自らが「学習」により、適用するべきモデル等を決定する点にあります。
AIによる「学習」手段としての機械学習には、「教師あり学習」、「教師なし学習」、「強化学習」や最近流行の「深層学習(ディープラーニング)」等様々な種類のものがありますが、大きな枠組みとして、「学習用データ」を機械(コンピュータ)に入力し、「学習用プログラム」に基づいて、「学習済みモデル」を構築するという手順を踏む点は共通しています。そして、このようにして構築された「学習済みモデル」を現実のデータに適用し、「成果物」を得ることができます。
そうすると、AIビジネスでは、大きく分けて、①「学習用データ」、②「学習用プログラム」、③「学習済みモデル」および④「成果物」の4つがどのような保護を受けるかを意識することが必要になると言えます。
<AIによる成果物作成の流れ>
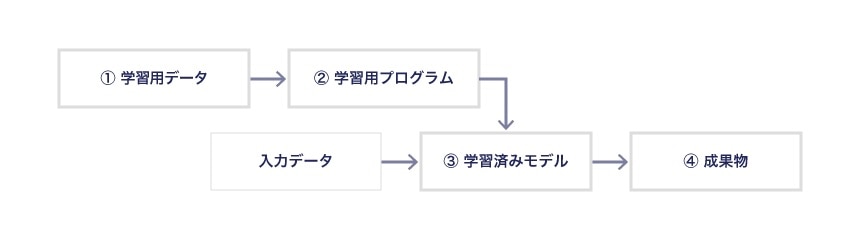
「学習用データ」の法的保護
自社データの保護と活用
通常、機械学習には膨大な量のデータが必要ですので、これをどこから集めてくるか、が問題となります。学術研究の場合には公開データの利用が比較的多いでしょうが、商業利用の場合には一般公開されていない自社データを利用する場合が多いと思われます。
自社データの準備には、そもそも、どのような観点からデータを集めるか、という判断も含めた生データの収集や、データの前処理(たとえば、一部の学習方法では、特徴量の抽出等)等、職人的なノウハウと多大な労力を要します。そのため、このような自社データは、ビジネス上大きな価値を有する場合が少なくありません。いかにしてこれを保護し、活用していくかは、AIビジネスにおける大きな法的課題です。
では、法的にはどのような保護が考えられるのでしょうか。
「営業秘密」としての保護
自社データは、一般的には社外秘とされている場合が多いと思われますので、秘密管理性、有用性および非公知性の3要件を充足すれば、不正競争防止法上の「営業秘密」(不正競争防止法2条6項)としての保護を受けることができます。
他方で、社内の学習用データを商品として販売する等、積極的に公開したい場合もあるかもしれませんが、これには注意が必要です。現在の知的財産法制上、データの保護範囲が狭いため、一度公開された学習用データの保護は一般的には難しいからです。
「データベースの著作物」としての保護
著作権法上は、学習用データが、検索のために「体系的な構成」(著作権法2条10号の3)を有し、かつその「情報の選択又は体系的構成」に創作性が認められる場合には、「データベースの著作物」として保護を受けることができます(著作権法12条の2第1項)。
もっとも、そもそもAIをビジネスに用いるのは、無秩序なデータ群からの有意義なモデルの構築または有意味な関係の発見に大きな目的がありますので、学習用データが、そのような「体系的な構成」を有していない場合もありうると思われます。
また、学習用データが「データベースの著作物」として保護を受けない場合には、そこに含まれる個々のデータが著作物に該当したとしても、情報解析のための複製等の例外規定(著作権法47条の7)の適用の可能性があり、ライバル企業による社内複製・翻案を甘受しなければならないという事態も生じうるところです。
「発明」としての保護
それでは、学習用データが、特許法上の「発明」として保護を受ける余地はあるのでしょうか。特許法は、「プログラム」を「物の発明」(特許法2条3項1号)として保護していますが、そもそも、学習用データが「プログラム」に該当するかが問題です。
特許法2条4項において、「プログラム」は以下のとおり定義されています。
② その他電子計算機による処理の用に供する情報であつてプログラムに準ずるもの。
①のような指令を含まないデータについて、ただちに「プログラム」該当性が認められるわけではないものの、②に該当する場合は、特許法上の「プログラム」に該当する余地があるといえます。
ただし、「プログラム」該当性の問題をクリアしたとしても、そのようなデータが「発明」といえるかどうかは、次の問題となります。特許法上では、「発明」とは、「自然法則を利用した技術的思想の創作のうち高度のものをいう」(特許法2条1項)とされているところ、学習用データが「自然法則を利用した」ものといえるのでしょうか。
現在の特許審査基準上、ソフトウェア関連発明が、発明と認められるためにはハードウェア資源を用いた技術的思想の創作であることが必要とされているため(特許・実用新案審査基準第III部第1章2.2(2))、データが何らかの構造を有し、ハードウェアを用いた処理を必要とする場合には、「発明」に該当しうると考えられます。他方で、データそのもののみでは、この基準を満たすことが難しいと判断される可能性は否定できません。そうすると、少なくとも審査段階では、特許法による保護を図ることは容易ではないでしょう。
民法上の不法行為としての損害賠償請求
また、仮にこれら知的財産法上の保護を受けなくとも、民法上の不法行為(民法709条)としての損害賠償請求による事後的な救済を得ることができるかという点についてはどうでしょうか。
これは、北朝鮮映画事件最高裁判決(最高裁平成23年12月8日判決・民集65巻9号3275頁)が、著作権法上保護が否定される製作物の利用に対しては、「同法が規律の対象とする著作物の利用とは異なる法的に保護された利益を侵害するなどの特段の事情がない限り、不法行為を構成するものではない」と判示しており、原則として否定されることになると思われます。
この点、同最高裁判決に先立ち、著作物性が認められない記事の見出しをデッドコピーした事案について、記事の見出しが、相応の苦労・工夫により作成されたものであることや、有料での取引対象とされる等の事情を考慮して、不法行為の成立を認めた裁判例(知財高裁平成17年10月6日判決)もありますが、同最高裁判決の下、このような判断が学習用データにも下されるかどうかは、今後の裁判例の集積を待たざるを得ません。
そうすると、現行法制上は、一度公開された学習用データの法的な保護は難しく、その公開を検討するにあたっては、この点を十分に意識しておくことが重要となると思われます。
「学習用プログラム」の法的保護
一方、学習用プログラムの法的保護について見てみると、プログラムのコードそのものは著作権法上の「プログラムの著作物」(著作権法2条10号の2)として、また、アルゴリズムは特許法上の「物の発明」(特許法2条3項1号)として、それぞれ保護を受けることができます。
加えて、学習用データと同様に、企業等内で社外秘情報として保護されているものであれば、不正競争防止法上の秘密情報(不正競争防止法2条6項)として保護を受けることができます。
「学習済みモデル」の法的保護
学習済みモデルそのものの法的保護
学習済みモデルは、通常、関数、行列またはパラメータ等の形式で自動的に出力されますので、それ自体は創作性または発明性が否定されることもあり、著作権法または特許権法による保護の対象とすることが難しい場合が多いと思われます。
ただし、事案によっては、学習用データの準備から、学習用プログラムへのデータ入力そして学習済みモデル出力に至るまでの一連の行為を全体的に捉えたうえで、これら一連の行為の成果物である学習済みモデルに創作性または発明性を認めることが適当と判断される可能性もあると思われます(このような場合には、特許法上、「方法の発明」としての保護の可能性も考えられます)。また、営業秘密としての保護を図ることも可能です。
学習済みモデルを用いた製品の法的保護
他方、学習済みモデルを用いた製品を販売するに際しては、いずれかの段階で、プログラムとして記述することになりますが、その保護内容は、基本的には、学習用プログラムの場合と変わるところはありません。
学習済みモデルをコード化した製品を販売する場合、ソフトウェアのリバースエンジニアリング(既存の製品を分解等することにより、それが用いられる技術等を分析する行為)は、比較的容易に行いうるため、モデル自体は内部に留めて、不正競争防止法上の営業秘密として保護を図りつつも、出力結果のみを外部に渡す等の手段によりその外部流出を防ぐ企業も増えてくるでしょう。
また、このような製品そのものを販売する場合には、プロテクトをかけて、その保護を図ることも考えられますが、不正競争防止法上、プロテクトの回避装置の販売等は規制されているものの(不正競争防止法2条1項11号)、プロテクトの解除そのものは違法とされていませんので、その保護は限定的なものとなります。
蒸留モデルと法的保護
加えて、最近は、既存の学習済みモデルを用いて入出力を繰り返した結果を利用して「学習」を行うことにより、その学習済みモデルと同等の性能を有する新たなモデルを作り出す「蒸留(distillation)」という手法が問題とされています(参考:知的財産戦略本部 新たな情報財検討委員会第2回議事録)。
<蒸留のイメージ>

上述のとおり、学習済みモデルを作成するためには、多量の学習用データを用意する必要があり、かつ、大規模な計算機資源を用いて、実際に学習用プログラムを動かすことが必要な場合が少なくありませんが、それと比較して小規模の学習済みモデルを動かすことは容易であることが多いでしょう。そのため、一から学習済みモデルを構築するのと比較すれば、蒸留モデルでは、多大な時間と計算機コストを節約することができると言えます。機械学習の分野では、データ量削減の有効な手段として着目されているものの、ビジネス上は、フリーライドの問題が生じます。
蒸留モデルは、学習済みモデルそのものを複製しているのではなく、入力データと出力データを用いて、別のモデルを構築しているため、著作権法違反の認定が難しいと言えます。他方、特許法については、特許請求の範囲の書き方次第ではあるものの、ある入力データに対して、ある出力データを返すシステムとの抽象的なレベルで、学習済みモデルを特許化できるのであれば、蒸留モデルによる特許権侵害を追及する余地があるでしょう。
「成果物」の法的保護
誰が著作者、発明者にあたるか
「成果物」の保護のレベルでは、前提として、誰が著作者または発明者にあたるかが問題です。冒頭でも述べたように、AIには権利の享有主体性はなく、ここでの主眼は、学習済みモデルの利用者に権利が発生するか否かです(なお、学習済みモデルのプログラムの製作者は、そのプログラムの著作者ではあるものの、成果物の著作者にあたらないことが多いと思われます)。
一般的に、著作者は、「創作行為に実質的に関与した者」を、また、発明者は「技術的思想を当業者が実施できる程度まで具体的・客観的なものとして構成する創作活動に関与した者」(知財高裁平成20年5月29日判決・判時2018号146頁)をそれぞれ指すと理解されていますので、その認定には、具体的な状況における創作・発明への関与の度合いが問われます。
理論上の問題と実務での評価
この点、もしも、学習済みモデルの利用者が、あくまでも補助的手段として、そのモデルを利用している場合には、利用者の著作者性または発明者性を認めることは可能と思われますが、AIによる作業割合が増えるほど、極端に言えば、ボタンをクリックするだけの場合、利用者を権利者として認定できるのかは理論上問題となると思われます。
ただし、著作者または発明者の認定は、AI以外の分野でも、具体的事実関係に踏み込んだうえで総合的な判断を行わざるを得ない困難な問題ですので、学習済みモデルの直接的な利用のみをことさらにクローズアップする必要はないと言えるとも思います。そして、弱いAIを前提とする限りは、データの前処理等の段階で、職人的な技術者による実質的な関与があることも多いであろうことから、実務上は、従来の著作者・発明者の認定を超える問題ではないという評価が可能な場面も少なからず出てくると思われます。
おわりに − AIビジネスにおける特許戦略
以上のとおり、現在の知財法制上、AIビジネスの特許による保護範囲は、限定的です。そのため、法的保護を前提としてデータを公開するという戦略は、基本的には採り難く、クローズ戦略をベースとして、特許戦略を組み立てていくことになるでしょう。具体的には、AIの価値の源泉である学習用データまたは学習済みモデル自体をブラックボックス化したうえで、あくまでも、成果物のみを組み込んだ発明を特許取得の対象とする、という特許戦略が主流となるのではないかと思われます。また、その際、不正競争防止法の営業秘密に該当しないおそれがあるデータは、秘密保持契約書の締結等により契約上の手当てをしていくことも必要です。
加えて、機械学習に必要となる学習用データ、学習済みモデルおよびその実行に必要な計算機資源のすべてを自社で賄うことには莫大なコストが必要となることから、一部の企業を除いては、複数の企業あるいは大学等の研究機関との間で連携を行う場面も多くなると思われます。たとえば、創薬AIの分野での50社超の企業による連合設立の動きは記憶に新しいところです。
企業等による協働を行う場合には、ライセンス契約や共同開発契約あるいは事業提携契約等の各種契約を締結することになるでしょうが、学習用データ、学習用プログラム、学習済みモデルおよび成果物のいずれの要素を対象とするのか、また、機械学習を行う過程で生じるノウハウや中間成果物をどのように取り扱うか等を含め、具体的事案に即した検討・交渉が必要となるでしょう。
シリーズ一覧全2件

西村あさひ法律事務所・外国法共同事業
- IT・情報セキュリティ
- 知的財産権・エンタメ
- 国際取引・海外進出
- 訴訟・争訟
- ベンチャー
この特集を見ている人はこちらも見ています
-
AI、IoTに関連したビジネスにおける特許戦略
第2回 IoTビジネスと特許戦略
知的財産権・エンタメ

-
令和7年改訂「営業秘密管理指針」の主な改訂点
知的財産権・エンタメ
-
知財判決のココに注目
第5回 バンドスコア事件 − 著作権法が保護しない表現の模倣と不法行為
知的財産権・エンタメ
-
知財判決のココに注目
第4回 ドラクエ・リュカ事件 - キャラクター名は著作物として保護されるか
知的財産権・エンタメ
-
知財判決のココに注目
第3回 ドワンゴ対FC2事件 – 国境をまたぐインターネットビジネスと特許権の効力
知的財産権・エンタメ
-
メタバースと法
第3回 メタバースをめぐる米国の動向 – 管轄、準拠法、著作権侵害訴訟など
知的財産権・エンタメ