法務こそ生成AIの波に乗れ!「GVA manage」で実現する法務変革PR
法務部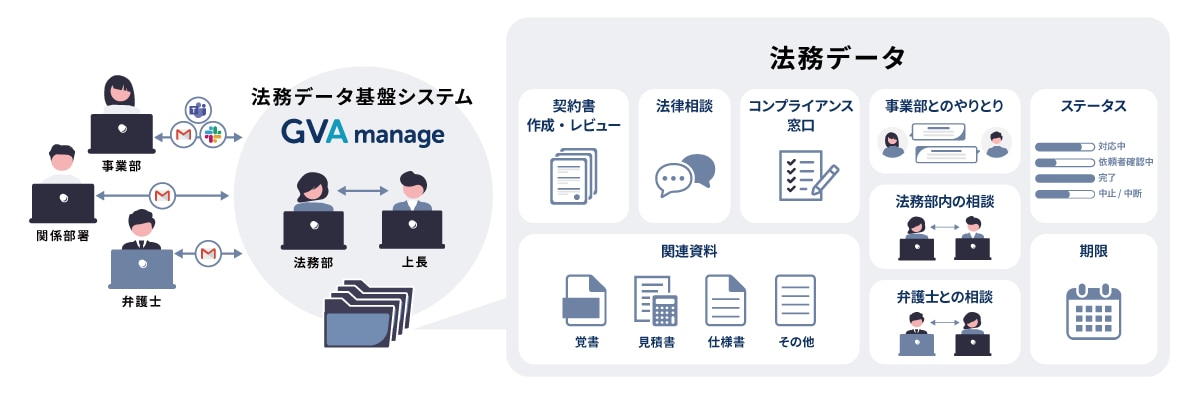
目次
近年、急速に発展・普及している生成AI。
直近では、飛躍的な精度向上により生成される文章や画像の質が大幅に改善され、業務効率化やコスト削減の面で大きなインパクトをもたらしています。
2023年9月時点で55%の企業が生成AIを試験運用または本稼動しているというデータ 1 もあり、早期導入することで競合他社に対して優位性を確保できる可能性が高まっています。
生成AI隆盛の時代、GVA TECH株式会社 代表取締役 山本俊氏は、「法務こそ、この波に乗るべき」と力強く語ります。法務部門は、大きなメリットとリスクを併せ持つ生成AIとどう付き合っていくべきか、山本氏に話を聞きました。

GVA TECH株式会社 代表取締役・弁護士 山本 俊 氏
弁護士登録後、鳥飼総合法律事務所を経て、2012年にスタートアップとグローバル展開を支援するGVA法律事務所を設立。
2017年1月にGVA TECH株式会社を創業。法務データ基盤システム「GVA manage」、AI契約書レビュー支援クラウド「GVA assist」やオンライン商業登記支援サービス「GVA 法人登記」等のリーガルテックサービスの提供を通じ「法律とすべての活動の垣根をなくす」という企業理念の実現を目指す。
生成AIで法務部門に訪れた変革のチャンス
AI活用の取り組みが社会的に進んでいます。法務に与える影響はどういったものがあるのでしょうか?
まず、大幅な業務効率化が挙げられます。
近年の法務部門は人手不足が深刻です。ここ10年20年、もしかしたら私が法務の世界に入る何十年も前からかもしれませんが、経営にインパクトを与える、もっと経営視点に入るといった、付加価値が高い法務の理想像は常に存在していました。
しかし、現在までなかなか実現できていないのは、人手不足や効率化しづらい業務が多いという問題があったからだと思います。
契約書のレビューや管理、事業部からの相談対応に忙殺されてきた法務部門こそ、この生成AIによる変革の波に乗るべきではないかと感じています。
生成AIのハルシネーション問題とRAGによる解決
これまでも、AIを活用した法務部門向けのサービスは数多く提供されてきました。具体的に、生成AIは業務にどのような変化をもたらしたのでしょうか。
法務部門に関わるツールとしてAI契約書レビューを例に取ると、従来の技術では事前に学習させた契約書のパターンや条項を認識し、分類することが中心でした。これだと、契約書や条文の内容を自然言語の類似性でしか判断できません。回答も事前に準備されたデータベースから引き出すだけです。
しかし、生成AIは文章自体を生成することができるため、契約条項の改善案や代替案を提案する点で大きな進化を遂げています。ただし、サービスの提供自体は弁護士法の問題を十分に考慮する必要があります。
また、従来の生成AI、特にChatGPTのような大規模言語モデル(LLM)は、不確かな情報を生成するハルシネーション(AIが事実に基づかない情報を生成する現象)の問題が指摘されてきました。この解決策として注目されるのが、外部の知識ソースを活用するRAG(検索拡張生成;Retrieval-Augmented Generation)という仕組みです。
RAGは、AIに最新の検索データや社内のナレッジを追加することで、回答の精度を大幅に向上させます。根拠が重要視される法務部門にとっても大きな意味を持つ技術といえます。
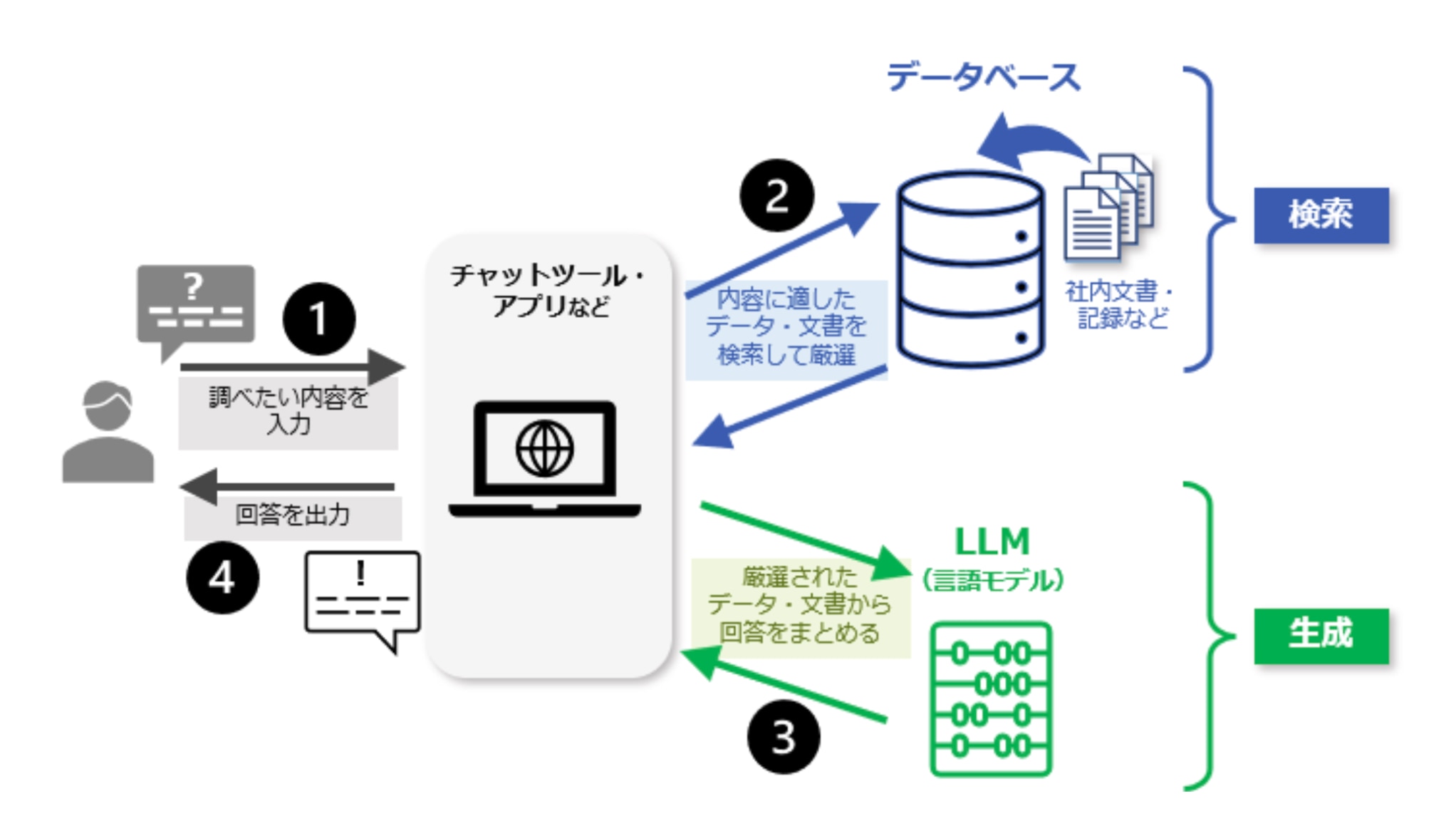
(https://www.fronteo.com/ai-learning/about-rag)
業務効率化の鍵 「法務データ基盤」の重要性
RAGによって、自社の法務データが有効活用できることは理解できました。ただ、そのデータをまとめる基盤が整備できていない企業も多そうです。そのような場合はどうすればいいのでしょうか?
これを説明するには、そもそも、「生成AIを活用するための法務データとはどういうものなのか?」という点を理解する必要があります。一般論としては、構造的に整理された一貫性のあるデータ群のことです。
例えば、案件名、取引先、依頼者の部署、担当者、相談の概要、背景事情や回答内容、契約書などと合わせて、契約類型、立場、作成者、作成日時などのメタデータを、案件単位にまとまった形で整備することですね。
法務の世界においては、構造化データが整備されていない企業が多そうなこともあり、そのままだとRAG活用までの道のりはかなり厳しいと感じています。
会社によって異なりますが、例えば契約書のバージョン管理は共有フォルダ、案件の管理はExcel、契約書の背景事情や交渉結果などの重要な情報は、法務部内外のやり取りを含めメールやチャットツールに保存されていることが多いでしょう。
こうしたデータが各ツールに分散している状態は、構造化データから最も遠い形です。これを解消するためには、全ての法務データを一つに集約したデータ基盤を構築することが重要です。
「GVA manage」が実現する法務データ基盤の自動構築と整備
これを人力でやるのは、現実的ではないですよね…
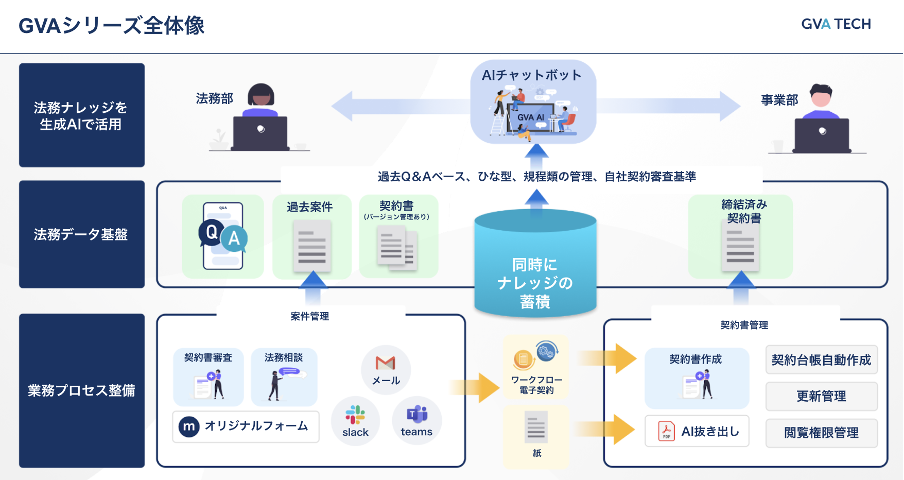
生成AIを活用した法務データ基盤は、「GVA manage」で効果的に構築できます。
GVA manage最大の特長は、案件管理を行うだけで同時に法務データが蓄積される点です。事業部から案件を受け付け、誰がどの案件をいつまでに処理するかを管理するだけで、案件単位の基盤が構築されます。
法務データ基盤の構築において一番の課題は、案件の背景にあたる事業部とのやり取りがデータ構造の外に逃げやすい点です。
GVA manageでは、事業部からの依頼時にフォーム内で適切な情報を選択してもらうことで、メタデータが整備された状態で依頼を受け付けることができます。
そして、メールやチャットツールと連携することで、案件に関連するメッセージのやり取りも集約して格納されます。
これにより、契約書のバージョン管理も自然に行えるようになり、案件管理と法務データ基盤作りを同時に進められるようになります。
案件管理と同時に行う法務データ基盤の構築は、法務業界でずっと解決されなかった課題に対する現実的な解決策です。法務データの管理作業に人的リソースを割くのは非効率的で、永続性のある解決策ではありません。
また、法務データ基盤構築において、重要なポイントが受付の整備です。
受付の整備が不十分だと、メタデータに不備が生まれ、結局は後の工程で手作業が必要になってしまいます。こうなると、データ基盤の構築が頓挫してしまうリスクが高まります。
法務データ基盤と生成AIで引き起こす変革
| 従来 | 生成AIを活用した場合 | |
|---|---|---|
| 新規案件の受付方法 | △ メールやチャットツールなどで受付 |
◯ フォームで一元的に受付 |
| 類似案件の探索 | △ 契約書の自然言語のみをもとに、手作業で過去の案件を調査 |
◯ 生成AIによる参考案件の提示 (部署、契約類型、立場など自然言語以外の情報も含む) |
| メタデータの整備 | ✕~△ 未対応もしくは後から手動での整備 |
◯ 案件受付時に必要なメタデータを自動整備 |
適切に整備された法務データ基盤と生成AIをかけ合わせると圧倒的な業務効率化を実現することができます。
例えば、新規案件が発生した際に、過去の類似案件をもとに対応のヒントを出してくれるようになると、法務としてはかなり嬉しいと思います。
新規案件において参考にする情報として、WEBサイトや第三者といった外部の情報だとピンとこないことも多いため、自社で対応した過去案件のデータを活用することが最も有効です。
これには、生成AIが類似案件をいかに探し出すかがポイントになります。生成AIは、契約書の中身等による自然言語の類似性のみでは、正確な判断ができません。
自然言語以外の情報、例えば、どの部署から来た案件か、契約類型、立場、取引先企業、具体的な質問内容といった要素と組み合わせることで、参考になる案件を提示することができます。
案件を受け付けた瞬間に必要なメタデータが整備されていれば、生成AIは適切な過去の案件を参照できます。例えば、生成AIに5つほどの類似案件をまとめてもらうことで業務効率化を図る、といったことも可能になります。
ChatGPTなどでは、入力する指示や質問(プロンプト)によっては質の高い回答が得られないこともあるかと思います。そういった点はいかがでしょうか?
RAGをうまく活用すれば、プロンプトの質に対する依存度は低くなります。
RAGは類似案件を基に適切な情報を提供するため、精緻なプロンプトはそれほど重要ではないですね。
おわりに
生成AIの進化により、法務部門も慢性的な課題である人手不足と業務効率化を解決できる時代が到来しています。
GVA manageを活用して、“理想的な法務” 実現の一歩を踏み出してみてはいかがでしょうか。
-
ビジネス+IT 「知らないと“損しかしない”生成AI「7つ」の活用リスク、覚えておくべき対策とは?」(https://www.sbbit.jp/article/cont1/138662#head1)内で紹介されている、ガートナーがエグゼクティブを対象に実施した調査 ↩︎
この特集を見ている人はこちらも見ています
-
BUSINESS LAWYERS COMPLIANCE 導入事例
第12回 「営業表彰の文化を、コンプライアンスにも」。"セゾンらしさ"で進める、全従業員参加型のコンプライアンス推進とBLC活用 PR
法務部
-
Legal Update
第54回 2026年7月に押さえておくべき企業法務の最新動向
法務部
-
BUSINESS LAWYERS COMPLIANCE 導入事例
第11回 内製のコンプライアンス研修からの脱却。法務イントラへの常設で実現した、"いつでも届く"コンプライアンス教育 PR
法務部
-
「いまさら聞けない法務の基本」シリーズ一覧―若手法務の基礎固めから経験者の知識アップデートまで
法務部
-
Legal Update
第53回 2026年6月に押さえておくべき企業法務の最新動向
法務部
-
BUSINESS LAWYERS COMPLIANCE 導入事例
第10回 「答え合わせができない仕事」に確信を。実務経験豊富な弁護士のロールプレイ研修で磨いた、グループ全体の内部通報対応力 PR
法務部