法務担当者がおさえておきたいAI開発契約8つのポイント
第2回 AI開発契約における権利・知財に関する問題を解決するには
IT・情報セキュリティ
シリーズ一覧全3件
目次
※本連載はSTORIA法律事務所 ブログ掲載の「「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント」の内容を元に加筆・修正したものです。
AIソフトウェア開発において権利・知財に関する交渉が難航する理由
AIソフトウェアの開発においては、通常のシステム開発以上に成果物の権利・知財に関する当事者双方の主張の対立が先鋭化することが多いのですが、その理由は以下の2点にあると思われます。
- 通常のシステム開発と異なり、AIソフトウェア開発においては複数の材料、中間成果物、成果物が存在する
- 開発に要する材料、中間成果物、成果物が高い価値を持ち、ユーザ・ベンダ共にそれらを独占/再利用したいという需要が存在する。
まず、通常のシステム開発の開発工程をごくごく単純化すると以下のように、「『ベンダの労力やノウハウ』という材料を投入して『プログラムや文書類』という成果物を開発する」ことになります。
【通常のシステム開発の開発工程】

一方、AIソフトウェアシステム開発の開発工程は、以下のように「『生データ、学習用プログラム、労力、ノウハウ』という材料を投入することで『学習済みモデル』や『学習済みパラメータ』という成果物を開発すること、開発の過程で『学習用データセット』や『発明、ノウハウ』といった中間的な成果物が生じる」という点が大きな特徴です。
【AIソフトウェアシステム開発の開発工程】
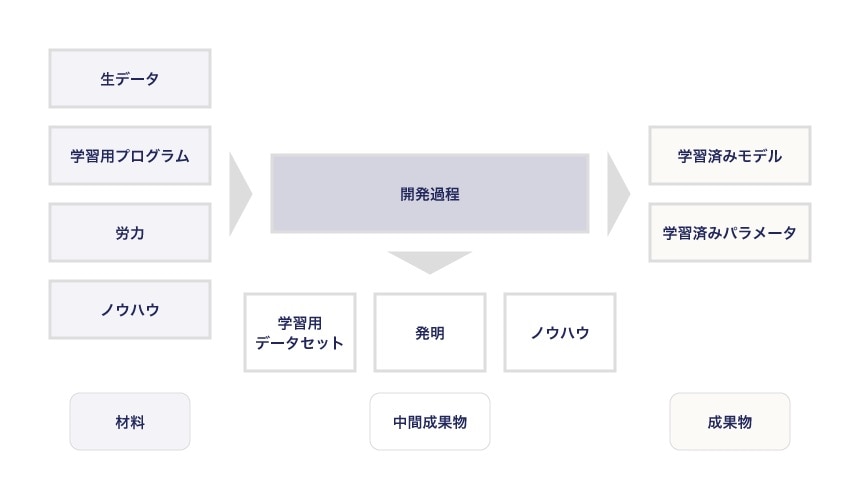
ちなみに、ここでいう「成果物」とは契約上、納品や作成支援が合意されているものを指します。したがって「成果物」と「中間成果物」の区別は相対的なものであり、契約内容によっては学習用データセットが成果物として合意されることもあります。
さらに、これらの材料、中間成果物、成果物が高い価値を持ち、ユーザ・ベンダ共にそれらを独占/再利用したいという意向を強く持ちます。
たとえばユーザが提供した生データを用いてベンダが学習済みモデルを生成するという典型的なケースを前提とすると、ユーザとベンダの成果物に関する意向は以下のように対立することになります。

そこで、この相反する2つの意向を調整する枠組みが必要となるのです。
ユーザとベンダの意向を調整するための枠組み
この点について、私は以下のような枠組みで整理すればよいのではないかと考えています。
- 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく
- ポイント1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく
- 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)
- 契約の限界を知っておく
「法律と契約の関係」についての一般論
上記にあげた4つのポイントを説明する前に、「法律と契約の関係」についての一般論について説明します。
まず、①「法律に書いてあることでも、契約で法律とは別の約束をすれば原則として契約の方が優先」します。
次に、②「契約に定めていないことがある場合、その点についての法律の規定があれば自動的に法律に従う。」ことになります。
2点目についてのイメージは下記のとおりです。
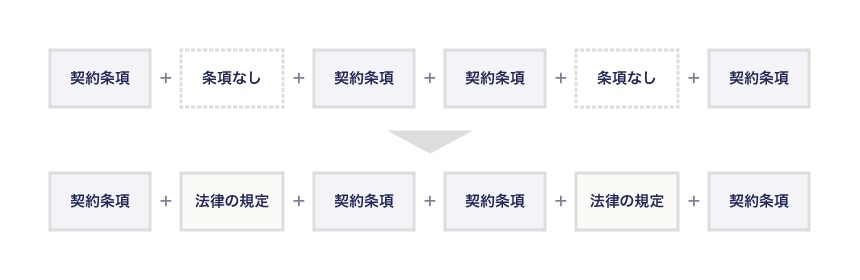
契約に定めていないことがある場合には、自動的に法律の規定が挿入されるイメージですね。そして、この「法律と契約の関係」を簡単にマトリクスにまとめるとこのような関係になります。
| 法律の規定 | 当事者間の契約なし | 当事者間の契約あり |
|---|---|---|
| あり | 法律の規定(デフォルトルール)がそのまま適用される | 法律の規定が当事者の契約どおり修正される |
| なし | ルールなし(原始状態) | 当事者の契約どおりとなる |
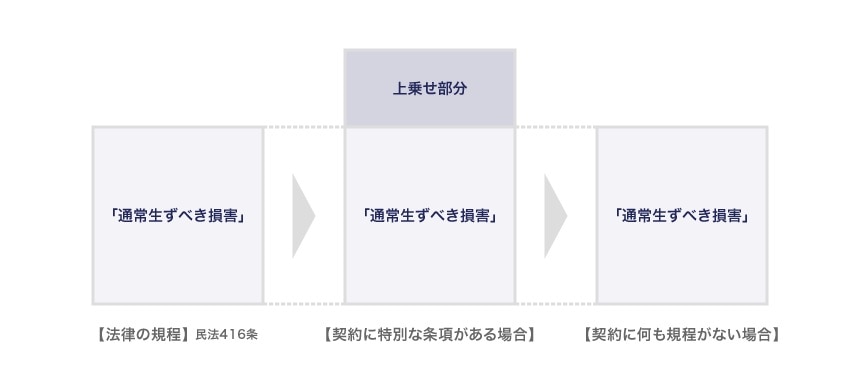
たとえば「委任契約において損害賠償に関して契約上特別の条項がある場合と、ない場合」を考えてみます。
債務不履行に関する損害賠償の範囲については民法416条に規定がありますが、それと別の契約上の条項(たとえば損害賠償の額を増額するなど)があった場合、その条項が法律に優先します。
逆に、損害賠償の範囲に関する条項が、契約上存在しなかった場合には、法律の規定通りとなります。
次に、「ハードウェアベンダが、ユーザの工場に納入した機器から生じるセンサデータを、ユーザからの同意を得てハードウェアベンダに送信した場合、当該センサデータをベンダはどの範囲で利用できるか」という事例について考えてみます。
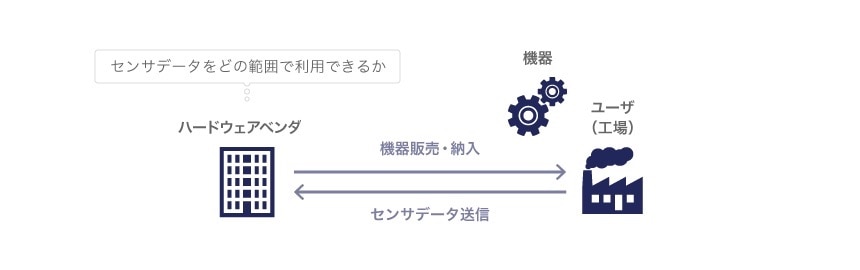
まず、センサデータについては、著作権などの知的財産権の対象ではありませんので、現行法上、誰が権利を持っているか、誰が利用できるか法律の規定が存在しません。
先ほどのマトリクスでいうと「法律の規定がない」という領域の話になります。
したがって、データの利用条件について、当事者間の合意が全くなかった場合には、法律上も、契約上も全くルールがない、つまり「原始状態」ということになります。
「原始状態」とは「持っている人が自由に使える」という意味であり、この例でいうと、ベンダはデータを自由に利用できるしユーザはベンダにデータの利用制限を課したり、データの引渡請求をしたりする法的な権利はないということを意味します。
もちろん、データの利用条件について当事者の合意がある場合は、当該合意に従います。たとえば「機器の保守管理目的のため」という合意があればその範囲でのみベンダはデータを利用できますし、それに加えて「ベンダのサービス・機器の改善のため」という合意があれば、その範囲でもベンダはデータを利用可能ということになります。
法律と契約の一般的な関係をAI開発にあてはめた場合はどうなるか
そしてこの一般的なルールをAI開発にあてはめるとこうなります。

前述の枠組みにおける、「ポイント1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく」という点はこのマトリクスの一番左の列に該当します。
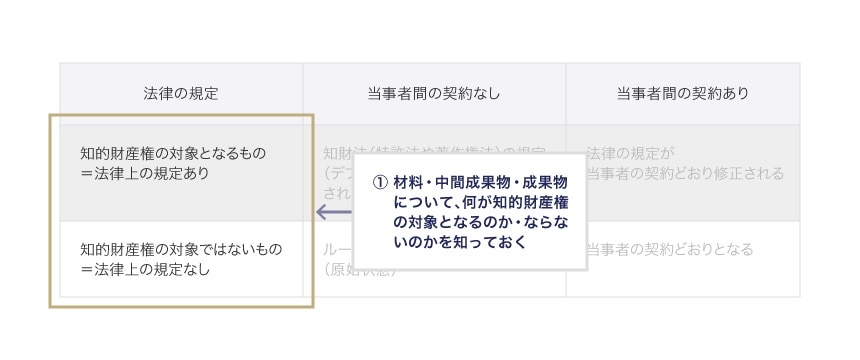
知的財産権の対象となるか・ならないのかを知っておく必要がある理由は、知的財産権の対象となるか・ならないかで、その帰属や利用条件についてデフォルトルール(=法律上のルール)があるか・ないかが異なるためです。
次に「ポイント2 ポイント1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく」という点は真ん中の列に該当します。

まず、何が知的財産権の対象になるかを知ったうえで、対象となるものについての法律(特許法、著作権法など)上のルールを知っておくということです。
そのうえで「3 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)」によって、法律上のデフォルトルール、あるいは「原始状態」を、契約でどのようにデザインするか考えます。
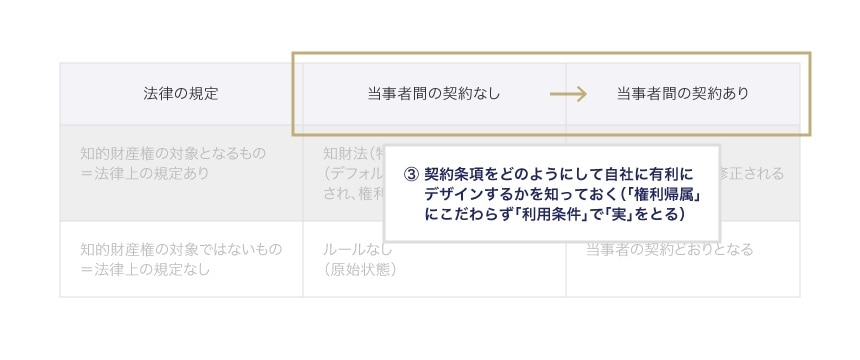
詳細は後述しますが、ここでのデザインの仕方が、AI開発契約における「権利と知財」に関する考え方の肝であり、AIガイドラインにおける非常に大きなポイントの1つです。
最後に「4 契約の限界を知っておく」という点は右列に該当します。
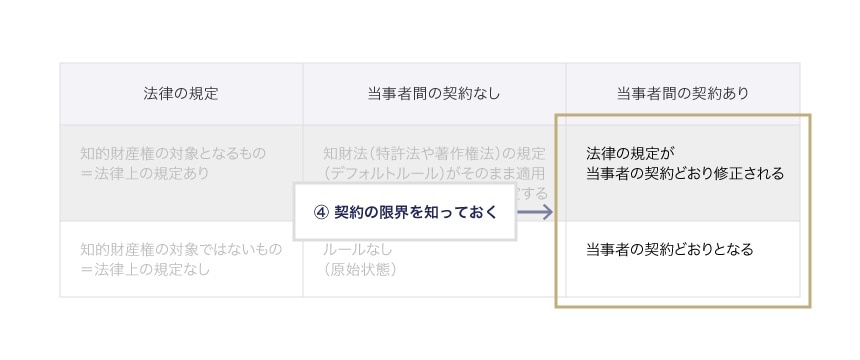
AIソフトウェアの場合、成果物等の権利帰属や利用条件を契約で定めていても、学習済みモデルに別のデータを用いて学習させた派生モデルや、入出力データのみを用いて別の学習済みモデルを生成する、いわゆる蒸留により生成された蒸留モデルに対して契約の効力が及ばない可能性があります。
それは契約の限界ではあるわけですが、AIソフトウェア開発の場合はその限界を知ることも重要です。
「知的財産権の対象となる・ならない材料・中間成果物・成果物」と「デフォルトルール」
それでは、ここから4つのポイントについてどのように検討を進めるべきか説明します。
「ポイント1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく」、「ポイント2 ポイント1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく」の2点はまとめて説明します。
AIソフトウェア開発において検討する必要がある対象物(材料・中間成果物・成果物)は、以下の6つです。
- 生データ
- 学習用データセット
- 学習用プログラム
- 学習済みモデル
- 学習済みパラメータ
- ノウハウ
これら6つの対象物を現行の知財法で保護しようとすると、特許法、著作権法、不正競争防止法(営業秘密等)の3つが考えられます。なお、不正競争防止法は「知的財産権」に関する法律ではありませんが、対象物が営業秘密や限定提供データに該当する場合には、その不正取得行為等が不正競争行為として差し止めや損害賠償請求の対象となりますので、同じように扱っています。
したがって、以下の表のブランク部分を埋めることが、ここでの目標になります。
| 特許法 | 著作権法 | 不正競争防止法 | |
|---|---|---|---|
| 生データ | |||
| 学習用データセット | |||
| 学習用プログラム | |||
| 学習済みモデル | |||
| 学習済みパラメータ | |||
| ノウハウ |
生データ
(1)知的財産権の対象となるのか・ならないのか
生データの種類によりますが、たとえば機械の操業データ、センサデータや事実を示すデータなどについて知的財産権は発生しませんので、「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当する限りにおいて、保護されることになります。
営業秘密等にも該当しない生データについては、法律上のデフォルトルールがないということになります。
(2)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等にも該当しない生データについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、そのような場合において生データを誰がどのように利用できるかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
学習用データセット
「学習用データセット」とは、生データに対して、変換・加工処理を施すことによって、学習作業を容易にするために生成された二次的な加工データのことを言います。
(1)知的財産権の対象となるのか・ならないのか
学習用データセットは、情報の単なる提示に過ぎないため、「発明」に該当せず特許を受ける権利の対象とはならないことがほとんどだと思われます。
もっとも、個々のデータに著作物性がない場合でも、学習用データセットが「データベースの著作物」(著作権法12条の2)に該当すれば著作権が発生します。
「データベースの著作物」とは「その情報の選択又は体系的な構成によつて創作性を有するもの」を言いますが、効率的な機械学習・深層学習のために、生データを取捨選択したり、体系的な構成で整理した学習用データセットは「データベースの著作物」に該当する場合も多いと思われます。
また、「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(2)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
学習用データセットが「データベースの著作物」に該当する場合、創作的な「情報の選択」または「体系的な構成」を行った者が著作権者となります。
したがって、ベンダのノウハウのみを利用して加工行為を行ったのであればベンダが著作権者となりますし、ユーザとベンダが共同して創作的な行為を行ったのであればユーザ・ベンダの共同著作物となって双方が著作権を共有するということもありえます。
学習用プログラム
(1)学習用プログラムとは
「学習用プログラム」とは、学習用データセットを利用して学習を行い、学習済みモデルを生成するためのプログラムを言います。
学習用プログラムは、ベンダがすでに保有しているものを利用する場合や、具体的開発案件に即して一から開発する場合など様々なケースがありますが、実際には、OSS(オープン・ソース・ソフトウェア)が利用されることも多々あります。
(2)知的財産権の対象となるのか・ならないのか
学習用プログラムは「プログラム」なので、通常のプログラムが知的財産権の対象となるかどうかと全く同じ話になります。
つまり、アルゴリズム部分は、特許法上の要件を充足すれば「物(プログラム)の発明」等として、特許法の保護を受けますし、ソースコード部分は著作権法による「プログラムの著作物」として著作権法上の保護を受けます(なお、オブジェクトコードに変換されても同様です。著作権法10条1項9号)
また、「営業秘密」(不競法2条6項) に該当すれば不正競争防止法で保護されます。
(3)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
法律上、特許を受ける権利を取得するのは発明者(作成者)であり、著作権を取得するのは創作者(作成者)ですから、当該プログラムを発明・創作した者が特許を受ける権利・著作権を取得することになります。
したがって、学習用プログラムをベンダが一から開発したのであれば法律のデフォルトルールとしてはベンダが、特許を受ける権利も著作権も取得することになります。
なお、OSSとして提供されている学習用プログラムを利用する場合には、ベンダ・ユーザ共にそのライセンス内容に注意する必要があります。OSSのライセンス内容によっては、ソースコードの開示義務などがあるためです。
学習済みモデル
(1)学習済みモデルとは
学習済みモデルは、学習用データセット同様、再利用可能であり、契約当事者の関心が非常に高い成果物です。
ただし、契約上・交渉上『学習済みモデル』という言葉が何を意味しているのかについて、慎重に見極める必要があります。
学習済みモデルは、「関数」「数理モデル」「アルゴリズム」「ネットワーク構造」「推論プログラム」「パラメータ」「それら各概念の組み合わせ」等多義的な意味を持っており、当事者が異なる意味で使うと大きなトラブルの原因となるからです。
契約書の締結・審査を行う法務担当の方は、ビジネス上の要件として、「学習済みモデル」としてユーザ・ベンダがどのような認識を持っているか確認する必要があります。
ここでは、AIガイドラインと同様、学習済みモデルとは「『学習済みパラメータ』が組み込まれた『推論プログラム』」を指すものとします。
(2)知的財産権の対象となるのか・ならないのか
学習済みモデルのうち「推論プログラム」部分については、学習用プログラムと同様に考えればOKです。
つまり、アルゴリズム部分は、特許法上の要件を充足すれば「物(プログラム)の発明」等として、特許法の保護を受けますし、ソースコード部分は著作権法による「プログラムの著作物」として著作権法上の保護を受けます。
たとえば、特定の開発課題の関係で非常に高い精度を持つ独自性の高いネットワーク構造を発見した場合、そのネットワーク構造については「物(プログラム)の発明」として特許出願が可能となる可能性があります。
また、「営業秘密」(不競法2条6項) に該当すれば不正競争防止法で保護されます。 学習済みモデルのうち「学習済みパラメータ」部分については後述しますが、結論的には知的財産権の対象にはならないものと思われます。
(3)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
これも、「推論プログラム」部分については、学習済みプログラムと同様、ベンダが一から開発したのであれば法律のデフォルトルールとしてはベンダが特許を受ける権利も著作権も取得することになります。
学習済みパラメータ
(1)学習済みパラメータとは
「学習済みパラメータ」とは、学習用データセットと学習用プログラムを用いた学習の結果、得られたパラメータ(係数)をいいます。
「学習用プログラムで自動的に生成される」「大量の数値の列」であり、ディープラーニングの場合で言うと、学習済みパラメータの中で主要なものとしては、各ノード間のリンクの重み付けに用いられるパラメータ等がこれに該当します。
(2)知的財産権の対象となるのか・ならないのか
先ほど説明したように、学習済みパラメータは、「学習用プログラムで自動的に生成される」「大量の数値の列」であって創作性がないことから「発明」にも「著作物」にも該当しない可能性が高いものと思われます。
もっとも「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(3)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等にも該当しない学習済みパラメータについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、学習済みパラメータを誰がどのように利用できるかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
ノウハウ
AIソフトウェアの開発に際しては様々なノウハウが必要となります。たとえば、「生データの取得・選択方法」「学習用データセットへの加工方法」「学習用プログラムを用いた効率的な学習方法」「学習済みモデルの本番環境における調製」などに関するノウハウです。
(1)知的財産権の対象となるのか・ならないのか
ノウハウについては、無形の情報ですので、著作権の対象にはなりませんが、「発明」の要件を満たすノウハウであれば特許を受ける権利の対象になりえます。「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(2)デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等や発明に該当しないノウハウについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、ノウハウを誰がどのように利用できるかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
「知的財産権の対象となる・ならない材料・中間成果物・成果物」と「デフォルトルール」のまとめ
以上をまとめると以下の表のように整理できます。
| 特許法 | 著作権法 | 不正競争防止法 | |
|---|---|---|---|
| 生データ | × | △ (著作物性がある データのみ) |
◯ (要件を満たす場合。 以下同様) |
| 学習用データセット | × | △ データベースの著作物に 該当する場合 |
◯ |
| 学習用プログラム | ◯ | ◯ | ◯ |
| 学習済みモデル | ◯ ただし推論プログラムの アルゴリズム部分 |
◯ ただし推論プログラムの コード部分 |
◯ |
| 学習済みパラメータ | × | × | ◯ |
| ノウハウ | △ 「発明」の要件を 満たす場合 |
× | ◯ |
なお、AIに関する知的財産権デフォルトルールについては、経産省の「オープンなデータ流通構造に向けた環境整備」(平成28年8月29日・経済産業省)にも類似の表が掲載されています(P82、以下「環境整備表」と言います)。上記の「まとめ表」と「環境整備表」との関係については、「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイントで解説していますのでご参照ください。
契約条項を自社に有利にデザインするには
これで、AI開発における6つの対象物についての法律上のデフォルトルールがわかりました。
次に重要なのは、そのデフォルトルールを前提として、契約条項をどのようにして自社に有利にデザインするかです。
AI開発契約におけるユーザとベンダの対立と解決のための考え方
AI開発契約における、権利・知財に関して、ユーザは、学習用データセットや学習済みモデルは、自社のノウハウや機密が詰まった生データを用いて生成されたものであり、開発に際して委託料も支払っているため、自社に権利があると考えます。一方で、ベンダは生データだけでは学習済みモデルは生成できず、自社のノウハウや多大な労力がなければ実現できないため自らに権利があると主張することがよく見られます。
このような対立は、ユーザ・ベンダいずれもが「成果物等は自社のものである」、言い換えると「成果物の権利を自己に帰属させる」ことに双方が固執することに主として起因しています。
そして、このように「どちらが権利を持っているか」(権利の帰属)に双方がこだわっている限り永久に双方の溝は埋まらず、交渉に多大な労力と時間がかかり結局双方が競争力を失うことになります。
本来、データ提供者(ユーザ)と学習済みモデル生成者(ベンダ)のビジネス構造は異なりますから、双方のニーズを同時に満たしうる契約条件は当事者双方が思うよりももっと多いはずです。
そこで、AIガイドラインにおいて提案しているのが「権利帰属」と「利用条件」を分離して柔軟な条件設定をすることです。
たとえば学習済みモデルにつき、「1 ユーザに権利を帰属させたうえで(「権利帰属」)」、「2 開発後、ベンダは一定期間の目的外利用や競業的利用は禁止される一方でユーザは当該学習済みモデルを自由に利用できる(「利用条件」)」等の対応をすることによって、当事者双方の利益に合致する契約を締結できる場合もあるでしょう。
言い換えれば「双方が対象物の『権利帰属』ではなく『利用条件』で『実』をとることを目指す」という発想です。
極端な言い方をすれば、自社が学習済みモデルに関する権利を保有しておらず、相手に権利がすべて帰属していても、交渉の結果「モデルの第三者提供を含め、何の制限もなくモデルを自由に利用できる」という利用条件を設定できれば、実質的にはモデルの権利を保有していることとほとんど同じ、ということです(もちろん、権利の譲渡の可否や権利者が移転した際の対抗力の問題など、「モデルの権利を保有しているのと完全に同じ」というわけではありませんが)。
とはいえ、交渉を進めるにあたり、自社の関係者が権利帰属にこだわりを見せる場面も少なくないかと思います。法務担当の方はできる限りビジネス要件を決める早い段階から検討に加わり、事業部門が満たしたいと考えるニーズ(権利化の必要性や、他社への展開の要否など)を把握することで円滑な交渉を推進することが求められます。
具体的な検討方法
このように「権利帰属」と「利用条件」を分けて考えるという発想に立つと、理屈としては、前述6つの対象物すべてについて「権利帰属」と「利用条件」を設定するということになります。なお、以下の図で生データについて「権利帰属」を定めていないのは、生データについては現行法上知的財産権が発生しないため、直接「利用条件」を定めれば足りるためです。もちろん、著作物など知的財産権が発生するデータについては「権利帰属」が問題となります。
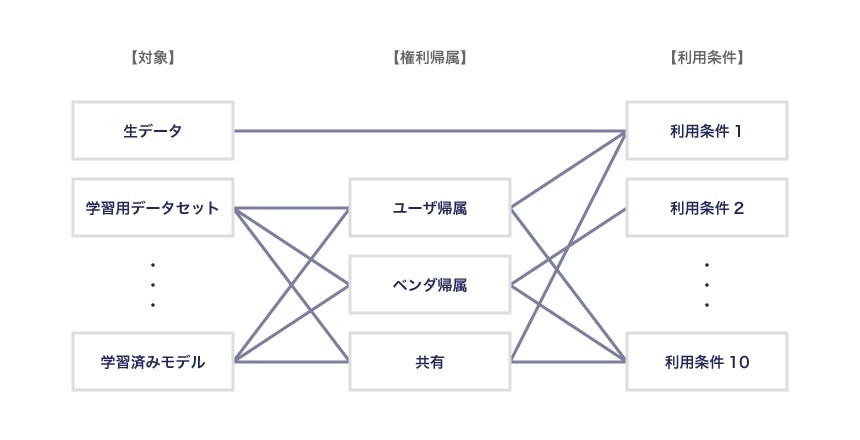
もっとも、実際にはもっとシンプルなパターンも多いはずで、AIガイドラインに附属している「 開発段階のソフトウェア開発契約書(モデル契約書)」では、「権利帰属」については第16条と第17条に、「利用条件」については第13条と第18条に定めています。
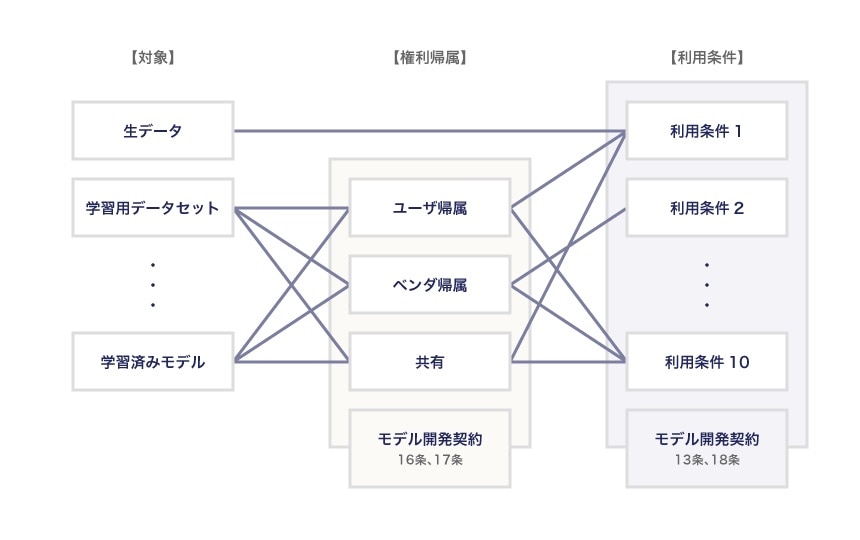
権利帰属について
権利帰属については、誰に権利帰属するかを合意する場合、以下の3パターンしかありません。
- ベンダ全部帰属
- ユーザ全部帰属
- ユーザ・ベンダ共有
AIガイドラインのモデル開発契約においては、成果物等のうち著作権の対象となるものは第16条に、著作権以外の知的財産権の対象となるものは第17条に定めています。
このように分けているのは、成果物等のうち「著作権の対象となるもの」(学習用データセットや学習済みモデルの推論プログラムのコード部分など)については、契約締結時点において、ユーザ・ベンダどちらに権利帰属するかを明確にしておきたいというニーズが強いと思われるためです。
一方、成果物のうち「著作権以外の知的財産権の対象となるもの」については、第17条で「本件成果物等を創出した者が属する当事者に帰属するものとする」(発明者主義)としています。
これは、「著作権以外の知的財産権の対象となるもの」については、どのようなものが発生するか契約締結時点では不明確なことも多いため、あらかじめ権利帰属について定めないこととしているのですが、もちろん「著作権の対象となるもの」と同様、「ベンダ全部帰属」「ユーザ全部帰属」「ユーザ・ベンダ共有」のいずれかとしても問題ありません。
なお、2007年に公表された経済産業省のモデル取引・契約書(第一版)(モデル契約2007)でも同じように「著作権」と「著作権以外」の条項が分けられており、今回のモデル開発契約もこれと同じ発想に基づいています。
モデル開発契約の関係条項をまとめたのが以下の表です。
| 著作権の権利帰属 (16条) |
著作権以外の知的財産権 の権利帰属(17条) |
|---|---|
| ベンダ帰属(A案) | 発明者主義 |
| ユーザ帰属(B案) | |
| ベンダとユーザの共有(C案) |
利用条件について
利用条件については、ユーザ、ベンダそれぞれが、材料・中間成果物・成果物を、自社のビジネスにおいてどのように利用したいかをよく検討しなければなりません。
たとえば、学習済みモデルの利用条件であれば、ユーザ・ベンダそれぞれがどのように自己のビジネスに利用するかは様々な方法が考えられ、以下の事項などを検討する必要があります。
- 自己の業務遂行に必要な範囲で、開発対象となった学習済みモデルを利用するだけなのか
- 学習済みモデルに新たなデータによる学習を行い、派生モデル(AIガイドラインでは「再利用モデル」と読んでいます)を生成するのか
- 学習済みモデルや派生モデルを第三者へ開示、利用許諾、提供等することがあるのか。
- 2、3の場合の相手方に対する利益配分(ライセンスフィー、プロフィットシェア)が必要かどうか
個人的には、実際の契約締結交渉においては「権利帰属」より、ここの「利用条件」をいかに自分のビジネスモデルに適合した形で設定できるか、ということのほうがよっぽど大事ではないかと感じています。
AIガイドラインのモデル開発契約では、3つの具体的なケースをあげ、それぞれのケースにおいて契約で利用条件をどのように定めたらよいかを例示していますので、ぜひ参考にしてください。
契約の限界を知っておく
これまで見てきたように、成果物等については、その権利帰属と利用条件をAI開発契約で定めることによって、ユーザ・ベンダそれぞれが、自分のビジネスに必要な範囲で利用できるように設定することができます。
ただ、実際には、成果物等そのものに関して権利帰属と利用条件を定めるだけでは、ユーザ・ベンダの権利を十分守れないことがありえます。
特に学習済みモデルについては、派生モデルや蒸留モデルの生成が可能であることからその危険性が顕著です。
派生モデルとは
派生モデルというのは、ある学習済モデルに対して新しいデータを利用して再学習させた結果できたモデルのことです。
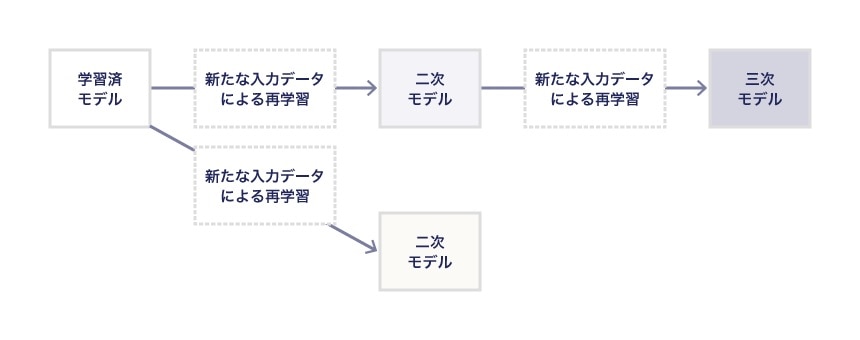
元のモデルより、より精度の高いものができますが、再学習によりパラメータが更新されるため、少なくともパラメータ部分については元のモデルと全く異なる形になっていますし、フレームワークの種類によってはネットワーク構造も元モデルと異なる形になります。
蒸留モデルとは
蒸留とはこういう行為です。
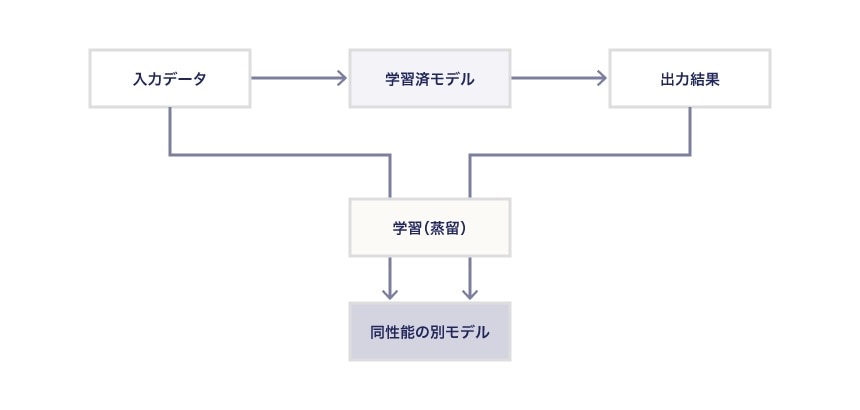
要するに学習済モデルを直接コピーしなくても、入力データと出力データを用いて別途学習をすることで全く異なるモデルを生成できる、という行為です。
これにより、性能がほとんど変わらず、かつ軽量なモデルができると言われています。
しかも、この蒸留行為は、学習済モデルが外から見えない状況(ブラックボックス化された状況)になっていても可能です。
「蒸留」行為の問題点は、派生モデルと同様、元のモデルと全く異なる形になっている、つまり元のモデルとの関連性が存在しない点です。
契約における対応方法
派生モデル・蒸留モデルはこのように元のモデルとの関連性が存在しないことから、AI開発契約において、開発対象となった学習済みモデルの権利帰属・利用条件を定めた条項を設置していても、その条項の効力が及ばない可能性があることになります。
そこで、AI開発契約において以下の内容を定めた条項を設置することが考えられます。
- リバースエンジニアリング、派生モデル生成、蒸留行為を明示的に禁止する(モデル開発契約19条)
- 同等または類似した機能を持つ学習済みモデルを用いることで行うことができる事業を一定の時期や範囲で制限する
なお、2については独占禁止法への抵触に注意する必要があります。
まとめ
AI開発契約においては、権利・知財についてユーザ・ベンダの意見が対立するケースが多く見られます。今回ご紹介した枠組みやAIガイドラインを参考に、法務担当が交渉・契約を円滑に進めていただければと思います。
シリーズ一覧全3件

STORIA法律事務所
- IT・情報セキュリティ
- 知的財産権・エンタメ
- 訴訟・争訟
- ベンチャー
この特集を見ている人はこちらも見ています
-
令和8年改正個人情報保護法の衆議院・参議院の附帯決議(各14項目)の全文と比較分析
IT・情報セキュリティ

-
ランサムウェア被害時のフォレンジック調査はどう進む? 費用・期間・対応フローと平時の備えを専門家に聞く
IT・情報セキュリティ
-
宇賀克也教授に聞く令和8年個人情報保護法改正
IT・情報セキュリティ
-
サイバー法令は「リスクマネジメントのツール」 海外サイバー規制動向とセキュリティ実務への影響を弁護士に聞く
IT・情報セキュリティ
-
AIに個人情報を入れてはいけない? 個人情報保護法改正を見据えて弁護士が解説
IT・情報セキュリティ
-
令和8年改正個人情報保護法の概要を改正項目ごとに弁護士が解説
IT・情報セキュリティ