法務担当者がおさえておきたいAI開発契約8つのポイント
第1回 AIソフトウェア開発における現場の悩みと、開発契約における「性能保証」「検収」「瑕疵担保」の扱い
IT・情報セキュリティ
シリーズ一覧全3件
目次
※本連載はSTORIA法律事務所 ブログ掲載の「「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント」の内容を元に加筆・修正したものです。
AI開発契約におけるユーザ・ベンダの悩み
2018年6月15日、経済産業省によって「AI・データの利用に関する契約ガイドライン」が策定されました。AIソフトウェア開発に関する契約について、ユーザ・ベンダ双方からご相談をいただくことも多くありますが、このガイドラインはAI開発契約を締結する際の一定の指針となります。筆者もこのガイドラインのうちAI編の検討委員・作業部会委員を務めました。
AI開発契約において筆者がご相談をいただく内容を分類すると、ほぼ以下の3つの領域に収まります。
- AI開発契約において「性能保証」「検収」「瑕疵担保」についてはどのように定めればいいのか(性能保証、検収、瑕疵担保)
- 生成された学習用データセット、学習済みモデル、学習済みパラメータなどは誰がどのような権利を持っているのか(権利・知財)
- AI開発・利用に際して生じる可能性のある損害についてAI開発契約ではどのように定めたら良いか(責任)
これら現場の悩みは一言で言うと「AIソフトウェア開発と通常のルールベースのソフトウェア開発との相違」に由来するのですが、特に2の「権利・知財」に関してはユーザ・ベンダ双方の主張が激しく対立し、開発契約の締結交渉に非常に長い時間がかかり、結局破談になったり他社に遅れを取って競争力を失うケースなどがあります。
AI開発契約において、上記3領域についての交渉がうまくいかないということは、個々の企業の不利益に直結しますし、ひいては日本のAI開発にとっても大きな障害となります。
そこで、本連載は「AI・データの利用に関する契約ガイドライン(AI編)」(以下「AIガイドライン」といいます)をもとにAI開発契約における8つのポイントを3回にわたって解説します。
なお、これらの記事はAIガイドラインを題材にした筆者個人の見解であって、「ガイドラインの概要」や「ガイドラインのエッセンス」ではありません。ましてやガイドラインの公的な解釈ではないことを、あらかじめお断りいたします。
また、「AI」という用語の意味は多義的ですが、AIガイドラインでは「AI技術」のことを「『機械学習』、またはそれに関連する一連のソフトウェア技術のいずれか」という意味で使っていますので、本記事では「AI」という用語を「(統計的)機械学習」という意味で使っています。
本連載で解説する8つのポイントは以下のとおりです。
第1回 性能保証、検収、瑕疵担保
- AIの特性と限界の相互理解
- プロセス・契約を分割する
- 開発契約の内容を工夫する
- 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく
- ポイント4について、デフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく
- 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)
- 契約の限界を知っておく
- AI開発における「責任」の種類を知り、契約でコントロールする
第2回 権利・知財
第3回 責任
AI開発契約で「性能保証」「検収」「瑕疵担保」が問題となる理由
「性能保証」、「検収」、「瑕疵担保」は、AI開発契約の契約交渉で問題となることが非常に多い領域です。
具体的には以下のようなご質問がよく寄せられます。
- ユーザから学習済みモデルを用いた出力の精度について一定の保証をするように強く要請された場合、AIベンダはどのように対応すべきか
- AI開発契約において検収基準や瑕疵担保についてどのように定めたら良いか
AI技術を用いない通常のシステム開発契約においては、成果物の性能についてベンダが一定の性能を保証したり、成果物について一定の検収基準に従った検収をユーザが行って合否の判定を行ったり、成果物について瑕疵が存在した場合の瑕疵担保責任を定めるのが通常です。
そのため、AI開発契約においても、ユーザはベンダに対して一定の性能保証、検収規定や瑕疵担保条項を盛り込むように要求するケースが多く見られます。
しかしAIソフトウェアの場合は、その技術的特性から以下の特徴を有しており、ベンダはユーザの性能保証などの要求に応じられず、ベンダとユーザの歩み寄りが不可能となってしまうケースがあります。
- 訓練データに統計的バイアスが含まれることが避けられないため、未知のデータに対する性能保証は原理的に困難
- 何か不具合が生じた場合でも、その原因(データの品質、ハイパーパラメータ設定、ソースコードのバグ等)が複数存在し問題の切り分けが困難
- 成果物の検収に際して学習に利用しない独立したデータセットが必要であり、かつ当然のことだが未知データでのテストが不可能
AIソフトウェア開発において「性能保証」、「検収」、「瑕疵担保」に関する双方の意見が対立する原因は、通常のシステム開発が「演繹的」な開発手法であるのに対して、AIソフトウェア開発が「帰納的」である点があげられます1。
「演繹」とは、一般的な前提やルールから結論を得る考え方です。三段論法はその典型例とされており、「A=B」「B=C」「よってA=C」という三段論法は法学部生であればおそらく最初の授業で習うはずです。
一方「帰納」とは、複数の個別事例や経験則などの前提を集めて、そこから普遍的な法則を見いだす考え方です。
通常のシステム開発は、まず仕様を確定したうえで、その仕様を実現するためにはこうする必要がある、ということを積み重ねてシステムを開発する、演繹的な開発手法をとります。
一方、AI開発は、開発目的との関係で意味のあると思われる大量のデータを集めてきて、それを用いて学習をさせ、当該データに共通する法則・特徴を見つけ出そうという帰納的な開発手法をとります。
帰納的な開発手法により開発されたAIは、理屈を積み上げて開発したわけではないので、訓練に使っていないデータを入力した場合、どのような挙動をするかが予測困難なため、「未知のデータでの性能保証は困難」ですし、「なにをもって『瑕疵』というかはっきりしない」ということになります。
ちなみに、AIソフトウェア開発案件において、当初ユーザサイドのビジネス部門や技術部門とベンダとが盛り上がり、その話がユーザサイドの法務・知財部門に上がった瞬間にストップがかかるケースは多く見られます。これは、「性能保証・検収・瑕疵担保」の考え方が通常のシステム開発とはかなり違うことが一因といえます。
「通常のシステム開発とAIソフトウェア開発の違い」を乗り越える3つのポイント
AI開発契約締結に際して、「通常のシステム開発とAIソフトウェア開発の違い」を乗り越えるためのポイントは以下の3点と考えています。
- AI開発の特性をユーザとベンダが理解すること
- 開発プロセスおよび契約の分割
- 契約内容の工夫
AI開発の特性をユーザとベンダが理解すること
通常のシステム開発とAIソフトウェア開発においては、そもそも開発手法の発想が異なる点についてユーザ・ベンダが共通認識を持つことがとても重要です。
実はAIガイドラインも、この点を強く意識して作られました。
このガイドラインが、かなりの分量を割いてAI技術について記述している(「第2 AI技術の解説」)のはそのためです。
AI開発に関して、技術者向けの書籍や情報は多数存在していますが、企業の法務・知財部門の方がAIソフトウェアの技術的特性やAI開発と通常のシステム開発の相違を学べるような平易な書籍類はこれまでなかったように思います。
ユーザとベンダの契約交渉が煮詰まる前に、法務・知財部門の方々はAIガイドラインを参考として、AIソフトウェア開発の特性を理解いただければと思います。
開発プロセスおよび契約の分割
次に重要なのが「開発プロセスおよび契約の分割」です。
AIソフトウェア開発の特徴を非常に乱暴に言ってしまうと「どのようなものができあがるか事前に予測することがユーザ・ベンダ双方にとって困難であること」、要するに「開発を進めてみないと、うまくいくかどうかわからない」という点にあります。
「うまくいくかどうかわからない」というのは「ベンダはわかっているけどユーザはわからない」という情報の非対称性の話ではなく、「ベンダもユーザもわからない」ということを意味しています。
このような特徴はユーザ・ベンダに双方にとって大きなリスクとなります。
このリスクをコントロールするための一つの方法としてAIガイドラインで提唱しているのが開発プロセスおよび契約を分割する「探索的段階型」の開発手法です。具体的には、AIソフトウェアの開発を、①アセスメント段階、②PoC2 段階、③開発段階、④追加学習段階の4段階に分けた開発手法です。
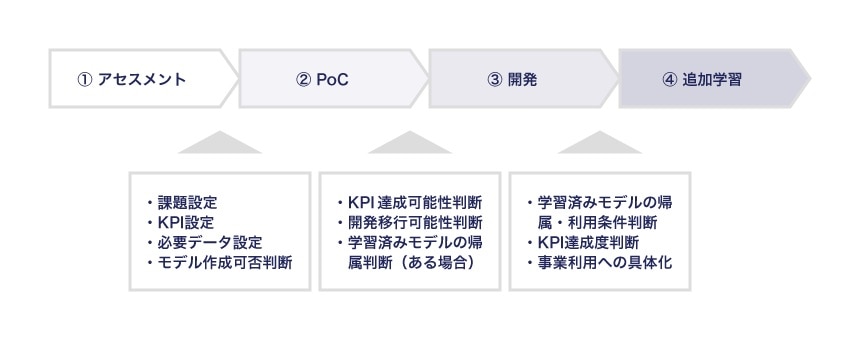
各段階の目的・成果物・契約内容の概要は以下のとおりです。
| アセスメント | PoC | 開発 | 追加学習 | |
|---|---|---|---|---|
| 目的 | 一定量のデータを用いて学習済みモデルの生成可能性を検証する | 学習用データセットを用いてユーザが希望する精度の学習済みモデルが生成できるかどうかを検証する | 学習済みモデルを生成する | ベンダが納品した学習済みモデルについて、追加の学習用データセットを使って学習をする |
| 成果物 | レポート等 | レポート等 | 学習済みモデル等 | 再利用モデル等 |
| 契約 | 秘密保持契約書等 | 導入検証契約書等 | ソフトウェア開発契約書 | 例:保守契約、学習支援契約または別途新たなソフトウェア開発契約など |
出典:AIガイドラインより一部変更のうえ引用
ちなみに「4つの段階に分ける」こと自体が重要なのではなく、「うまくいくかどうかわからないから少しつずつ進めていって、うまくいきそうなら次のステップに行き、無理そうなら中止する。それによってユーザ・ベンダ双方のリスクをコントロールする」という点が本質です。
そのため、開発規模によっては、①アセスメント段階、②PoC段階が一体となることもあるし、②PoC段階を更に複数に分割することもあります。
契約内容の工夫
通常のシステム開発とAIソフトウェアの開発における契約内容を対比すると以下のようになります。
| 通常のシステム開発 | AI開発 | |
|---|---|---|
| 契約の法的性質 | 工程によって異なる(上流工程は準委任型、下流に行くにしたがって請負型) | 全工程で準委任型が親和的 |
| 完成義務 | 請負型が適用される工程では完成義務あり | なし(モデル開発契約7条)。 ただし成果完成型の準委任契約も締結可能。 |
| 性能保証 | 請負型が適用される工程では合意可能 | なし(モデル開発契約7条)。 ただし、一定の既知データを用いた場合の性質であれば保証可能な場合もある。 |
| 瑕疵担保責任 | 請負型が適用される工程においては瑕疵担保責任あり | なし |
私はセミナーなどでこの図を使って説明することが多いのですが、そこで一番聞かれる質問は「現場にAIソフトウェアを投入し、未知のデータが入力された場合に性能保証ができないのは理屈としてはわかった。しかし多額のお金を支払って開発したAIソフトウェアが一切性能保証できない、というのはやはりユーザとしては納得し難い。契約上の工夫でなんとかできないか」というものです。
この点についてガイドラインで提示されている方法は「学習に利用しない一定の既知の評価用データを入力した場合の性能保証を行う方法」と「準委任契約における成果完成型を選択する方法」です。
前者については未知データ入力の場合の保証は難しいとしても、既知の評価用データ入力の場合の保証は技術的には可能なことが理由としてあげられます。もっとも、この場合、当該評価用データが、AIを現場に投入した場合の実際の未知データの性質を十分に反映している必要があります。
後者については、準委任型契約には、委任事務の履行により得られる成果に対して報酬を支払うことを約する「成果完成型」と、委任事務の処理の割合に応じて報酬を支払う「履行割合型」があると言われており、そのうち「成果完成型」を選択するという意味です。
この「成果完成型」の準委任契約であれば、進捗に応じた一定の成果(たとえば既知データに対する一定の性能など)に対して固定金額を支払うという合意をすることになり、成果未達成の場合のベンダのリスクを下げることができると考えられます。
このような契約形態を採用する場合、ユーザ側の法務担当は事業部門とのコミュニケーションを密に行い、ベンダに保証してほしい「成果」「性能」とは具体的に何か、その「成果」「性能」が達成できた場合想定しているビジネス要件を満たせるか、などについて確認すべきと言えるでしょう。
-
「演繹的」と「帰納的」の詳細についてはこちらの記事をご覧ください。
参考:「渋谷の牛タン屋で横にいたカップルとAI開発における演繹と帰納について」(STORIA法律事務所ブログ 2018年5月22日) ↩︎ -
PoC(Proof of Concept)とは、概念実証のことであり、新たな概念やアイデアを、その 実現可能性を示すために、部分的に実現することを意味します(AIガイドラインより)。 ↩︎
シリーズ一覧全3件

STORIA法律事務所
- IT・情報セキュリティ
- 知的財産権・エンタメ
- 訴訟・争訟
- ベンチャー
この特集を見ている人はこちらも見ています
-
令和8年改正個人情報保護法の衆議院・参議院の附帯決議(各14項目)の全文と比較分析
IT・情報セキュリティ

-
ランサムウェア被害時のフォレンジック調査はどう進む? 費用・期間・対応フローと平時の備えを専門家に聞く
IT・情報セキュリティ
-
宇賀克也教授に聞く令和8年個人情報保護法改正
IT・情報セキュリティ
-
サイバー法令は「リスクマネジメントのツール」 海外サイバー規制動向とセキュリティ実務への影響を弁護士に聞く
IT・情報セキュリティ
-
AIに個人情報を入れてはいけない? 個人情報保護法改正を見据えて弁護士が解説
IT・情報セキュリティ
-
令和8年改正個人情報保護法の概要を改正項目ごとに弁護士が解説
IT・情報セキュリティ