生成AIとは? 各国の法規制、ビジネス利用時の法的論点をわかりやすく整理
知的財産権・エンタメ 更新
目次
昨今、大規模言語モデル(LLM)や拡散モデル(Diffusion Model)等を活用した生成AI(Generative AI)が大きな注目を集めています。その一方、生成AIによる著作権やプライバシー侵害等、生成AIをビジネス利用する際の法的問題が議論されています。
本記事では、生成AIの定義、各国の法規制や議論の動向、開発・利用にあたって留意すべき法的論点等について解説します 1。
生成AIとは
生成AIの定義
生成AIに関して、日本では、特に確立した定義はないものの、たとえば、2024年4月に公表された「AI事業者ガイドライン(第1.0版)」では「文章、画像、プログラム等を生成できる AI モデルにもとづくAIの総称」と定義されています。
欧州では、2023年6月に公開されたAI法(Artificial Intelligence Act)案の欧州議会修正版において、生成AI(Generative AI)が「複雑なテキスト、画像、音声、映像等のコンテンツをさまざまなレベルの自律性をもって生成することを特に意図したAIシステム」と定義されていました(同法案28b条)。2024年5月に成立したAI法では、生成AIを含む汎用目的AIモデル(General-purpose AI models)が、「大量のデータを用いた自己教師あり学習で訓練された場合を含め、顕著な汎用性を示し、モデルが市場に出された方法に関わらず、幅広い異なるタスクを有能に遂行でき、さまざまな下流システムやアプリケーションに統合できるAIモデル」と定義されました(AI法3条(66))。
本記事では、何らかのコンテンツを出力するAIを「生成AI」と呼びます。
生成AIサービスの具体例
現在、生成AI関連の各種サービスが提供されており、その内容はさまざまです。たとえば、入力(プロンプトと呼ばれることもあります)と出力がテキストであるtext-to-text型の代表的サービスとしては、ChatGPT、Perplexity AI、Microsoft copilot、Gemini、Claude 2、GitHub Copilot(コード生成)等があります。また、入力をテキストとし、出力を画像とするtext-to-image型の代表的サービスとしては、MidjuourneyやDALL•E2があり、音声を出力するtext-to-voiceのサービスとしてはVoicevoxがあります。
なお、複数の種類の入力を処理することができるAIを「マルチモーダルAI」と呼ぶことがあります。
現時点では、主に生成AIにより出力されたコンテンツによる各種権利・利益の侵害に注目が集まっている感は否めません。もっとも、このようなコンテンツ出力の可能性が低い業態や利用態様も少なくなく、そのため、生成AIの具体的な応用可能性がより明確になった段階で、各種ユーザインターフェースへの統合等、むしろ、生成AIと既存の各種サービスとの連携等の手段による実用化が問題になる状況も考えられるでしょう。
なぜ生成AIなのか
なぜ今、生成AIがこれほどの注目を集めているのでしょうか。
これまでもAIの利活用自体は行われていましたが、大量の学習用データセットを用いた学習により、基盤モデルの汎用的な性能(学習用データセット以外のデータに対する回答能力)が向上したことが挙げられるでしょう。生成AI以前のAIでは、ある学習済みモデルを特定目的のために利用をする場合、学習済みモデル全体を再学習(転移学習やファインチューニング等)する必要があることが少なくありませんでした。
他方、生成AIの基幹技術である基盤モデル(LLM等を含みます)は、大量の学習用データセットにより学習されているため、汎用的な性能(汎化性能)が高く、そのため、少量のデータセットによる再学習で実用化が可能となりました。そのため、再学習のコストが下がった状況にあります。
また、従前、AIは、画像認識や音声認識、自然言語処理等の分析や予測のような特定機能の実装に主に用いられており(このような推論等を行うAIを、生成AIと対比して「分析(系)AI」「識別(系)AI」と呼ぶこともあります)、一般のユーザが必ずしもAIを利用しやすい状況にはなかった面もあります。
これに対して、生成AIでは、大規模な学習用データセットを用いて学習することで、テキスト・画像・音声・動画・プログラム等の汎用的かつ高品質のコンテンツの制作が可能となったこと、また、各種基盤モデルの公開や、生成AIを用いたサービス(以下「生成AIサービス」といいます)の展開により、一般のユーザによる幅広い利用が可能になったこと等が、大きな注目を集める一因になっているでしょう。
生成AIをめぐる各国の法規制や議論の動向
生成AIの取扱いをめぐっては、国内外でさまざまな動きがあり、その規制や議論の動向等は注目に値します。
日本の動き
日本では、AIの利活用自体を直接規律する法律はなく、ガイドラインや自主規制等を含めた、いわゆるソフトロー的なアプローチをとっていることが特徴的です。
2023年5月に開催されたG7広島サミットで、AIに関する利活用の推進や規制に向けた国際ルールを検討することが確認されたことを受けて、同月26日、内閣府のAI戦略会議が「AIに関する暫定的な論定整理」を公表し、生成AIを含めたAIの利活用に関する論点整理を行っています。その後、経済産業省と総務省は、既存の複数のガイドラインを統合した、事業者向けのAIガバナンス実施の指針として、2024年4月に「AI事業者ガイドライン(第1.0版)」を公表しました。
もっとも、2024年6月に閣議決定された「統合イノベーション戦略2024」では、「今後、AIに関する様々なリスクや、規格 やガイドライン等のソフトローと法律・基準等のハードローに関する国際的な動向等も踏まえ、制度の在り方について検討する」とされ、これを受けて、法規制も視野に入れたAI規制の要否を検討するべく、同年8月より「AI制度研究会」が開催されています。
個別分野に目を向けると、知的財産の分野では、AIの利活用による知的財産権侵害への懸念の増加を受けて、2024年3月には、文化審議会著作権分科会法制度小委員会「AIと著作権 に関する考え方について」が、また、同年5月には、AI時代の知的財産権検討会「中間とりまとめ」が、それぞれ公表されました。その中では、知的財産権の保護に加えて、これら知的財産権による保護の対象とならない声等に関する保護にも言及があります。たとえば、「統合イノベーション戦略2024」では、「今後の技術発展や海外動向等も見ながら、俳優や声優等の肖像や声も含め引き続き必要な検討を進めていく」とされており、今後の議論の蓄積が期待されます。
また、個人情報の分野では、個人情報保護委員会が、2023年6月に、「OpenAIに対する注意喚起の概要」および「生成AIサービスの利用に関する注意喚起等」を公表しました。さらに、2024年6月に公表された「個人情報保護法いわゆる3年ごと見直しに係る検討の中間整理」では、次のような考えが示されています。
欧州の動き
欧州では、2024年5月にAI法(Artificial Intelligence Act)が成立し、同年8月1日に発効しました。
AI法は、AIシステムのリスクを「許容できないリスク(unacceptable risk)」、「高リスク(high risk)」、「限定的なリスク (limited risk)」、「最小リスク(minimal risk)」の4つに分けたうえで、そのリスクの程度に応じた規制等を課す、リスクベースアプローチを採用しています。
AI法では、1-1で述べたように汎用目的AIモデル(General purpose AI model)の定義が示されています。汎用目的AIモデルは他のAIシステムに組み込まれる可能性が高い一方、そのすべてを監視することが困難であること等の理由により、次のような透明性の義務が課されています(AI法53条。ただし、後述するシステミックリスクがないOSSの場合等、適用除外も定められています)。
- モデルの技術文書を作成し、最新の状態に保ち、AIオフィスや国家の管轄当局に提供する
- 汎用目的AIモデルを自らのAIシステムに組み込むことを意図するAIシステムのプロバイダに対して、汎用AIモデルの情報と文書を提供し、更新し続ける
- 著作権および関連する権利に関するEU法を遵守する方針を策定し、最先端技術を用いて権利の留保を遵守する
- AIオフィスが提供するテンプレートに従い、汎用AIモデルのトレーニングに使用されたコンテンツの詳細な概要を作成し、公表する
また、汎用目的AIモデルの中でも、特に高機能で影響力のあるAIモデルは「システミックリスクのある汎用目的AIモデル(general-purpose AI model with systemic risk)」と位置づけられ、各種の追加的な義務を負うものとされています。
ここでいう「システミックリスク」とは、「汎用目的AIモデルの高い影響を与え得る能力に特有のリスクを意味し、そのリーチによる、または公共の健康、安全、公的秩序、基本的権利、あるいは社会全体に対する実際または合理的に予見される悪影響による、EU市場への重大な影響を持ち、バリューチェーン全体にわたって大規模に拡散する可能性のあるリスク」と定義されています(AI 法3条 (66))。
ある汎用目的AIモデルが、システミックリスクを有するか否かは、適切な技術ツールおよび手法、指標やベンチマークを含む評価に基づいて、高い影響を与え得る能力を有するかにより判断されるものの、モデルの訓練のために用いられた累積計算量が浮動小数点演算(FLOP 2)で10の25乗を超える場合には、システミックリスクがあると推定されます(AI 法51条)。
システミックリスクのある汎用目的AIモデルには、次の各義務が課せられます(AI 法51条および55条)。
- システミックリスクに関する上記要件が満たされた場合または満たされることを認識してから2週間以内に欧州委員会に通知すること
- システミックリスクを特定し軽減することを目的としたモデルに対する敵対的テストの実施および文書化を含む、最新技術を反映した標準化されたプロトコルおよびツールに従ってモデルの評価を実行すること
- システミックリスクを有する汎用目的AI モデルの開発、上市、または利用に起因する可能性のあるシステミックリスクを、その発生源も含めて、EUレベルで評価し、軽減すること
- 重大なインシデントとそれらに対処するために考えられる是正措置に関する関連情報を追跡し、文書化し、不当な遅滞なくAIオフィス、および必要に応じてEU加盟国内管轄当局に報告すること
- システムリスクがある汎用目的AIモデルとモデルの物理インフラストラクチャに対して適切なレベルのサイバーセキュリティ保護を確保すること
AI法は、原則として、その発効後、24か月後(2026年8月2日)に完全施行されます。ただし、許容できないリスクのあるシステムの禁止事項は6か月後、汎用目的AIモデルに関する規制は、12か月後、高リスクのあるAIシステムに関する規制は36か月後に、それぞれ施行されるとされています(AI法113条)。
米国の動き
(1)AI権利章典:システム開発の際の5つの原則
米国では、2022年10月に公表された「AI権利章典(AI Bills of Rights)」において、AIを含んだ自動化されたシステム(Automated Systems)を開発する際の非拘束的な5つの原則が公開されています 3。具体的には、①安全で効果的なシステムであること、②アルゴリズム由来の差別からの保護の確保、③データプライバシーの確保、④ユーザへの通知と説明の実施、⑤人による代替手段等の実施が挙げられています。
(2)AI関連企業の動き:安全で透明なAI技術開発の自主的な合意
また、生成AIに関しては、2023年7月および9月に、著名なAI関連企業が、ホワイトハウスにおいて、次のとおり、安全で透明なAI技術開発をすることを自主的に合意(コミットメント)しています。
- AIシステムの公開前に内部および外部のセキュリティテストに取り組む
- AIリスクの管理に関する情報を産業界や政府、市民社会、学術界と共有する
- AIシステムの中で最も重要な部分である非公開のモデルの重みを保護するために、サイバーセキュリティと内部脅威対策に投資する
- AIシステムにおける脆弱性の発見と報告を第三者が容易に行えるようにする
- AIが生成したコンテンツであることをユーザが認識できるように、ウォーターマーキングシステムなどの堅牢な技術メカニズムの開発に取り組む
- AIシステムの能力、限界、適切なおよび不適切な使用領域について公開的な報告を行うことを約束する
- 有害な偏見や差別を回避し、プライバシーを保護するために、AIシステムがもたらす社会的なリスクに関する研究を優先する
- がん予防から気候変動の緩和に至るまで、社会の最大の課題に対処するために先進的なAIシステムを開発・展開する
(3)大統領令:各連邦機関が実施するべき措置等
その後、2023年10月、バイデン大統領は「人工知能(AI)の安心、安全で信頼できる開発と利用に関する大統領令」を発令しました 4。大統領令は主に、以下の8つの観点から、各連邦機関が実施するべき措置等を記載しています。
| ① 安全性とセキュリティーの新基準 | 国家や経済の安全保障、公衆衛生や安全性に重大なリスクをもたらす基盤モデルを開発する企業に対し、モデルのトレーニングを行う際の政府への通知、テスト結果の政府への共有を義務づけ。 |
| ②米国民のプライバシー保護 | 議会に対し、超党派のデータプライバシー法案を可決するよう要請。 |
| ③公平性と公民権の推進 | AIアルゴリズムが司法、医療、住宅における差別を悪化させるために利用されないよう連邦政府の請負業者に明確なガイダンスを提供。 |
| ④消費者、患者、学生の権利保護 | 医療面では、AIの責任ある利用と、安価で命を救う薬剤の開発を推進。教育面では、AIを活用した教育ツールを導入する教育者を支援。 |
| ⑤労働者の支援 | 雇用転換、労働基準、職場の公平性、安全衛生、データ収集に取り組む。 |
| ⑥イノベーションと競争の促進 | 「全米AI研究リソース」の試験運用を通じ、米国全体の研究を促進。 |
⑦外国における米国のリーダーシップの促進 |
国際的なパートナーや標準化団体との重要なAI標準の開発と実装を加速し、技術の安全性、信頼性、相互運用性を確保。 |
⑧政府によるAIの責任ある効果的な利用の保証 |
権利と安全を保護するための明確な基準や各省庁がAIを利用する際の明確なガイダンスを発行 |
2024年7月26日、ホワイトハウスは、大統領令で270日以内に実施されるものとされていた行動を予定どおり実施した旨を公表しています。
(4)州法:AIの利活用に関する一定の規制
加えて、州法レベルでも、AIの利活用に関する一定の規制を課す動きがあります。
- ユタ州
2024年5月1日に、ユタ州において、AIに関する州法「Artificial Intelligence Policy Act」(SB 149)が発効しました。
この法律は、生成AIの利用に関して、一部の規制された職種については、規制されたサービスを提供する際に、生成AIを利用していることを開示する義務が課せられ、また、ユタ州の消費者保護法の適用を受ける事業者も、消費者から問われた際等には消費者がやり取りしている相手が生成AIであることを開示する義務などを負います。さらに、生成AIが引き起こした消費者保護法違反についても、当該生成AIを利用する事業者が責任を負うことが明確にされています。
同法の違反には最大2,500米ドルの罰金が科され、さらに行政命令や裁判所の命令に違反した場合には5,000米ドルの罰金が科される可能性があります。 - コロラド州
2024年5月17日に、コロラド州でも、AIに関する州法「Consumer Protections for Artificial Intelligence」(SB 24-205)が成立しており、2026年2月1日に発効します。
この法律は、教育、雇用、金融、行政サービス、ヘルスケア、住宅、保険、法律サービスの提供に関して重大な法的効果を与える決定を行うハイリスクAIシステムに対し、アルゴリズムによる差別に関する既知のまたは合理的に予想されるリスクを防止するための具体的な義務を課しています。たとえば、ハイリスクAIシステムの開発事業者は同AIシステムに関する情報提供等を行う必要があり、利用事業者は同AIシステムの利用に関する詳細な影響評価を実施しなければなりません。
同法の違反には最大20,000米ドルの罰金が科される可能性があります。 - カリフォルニア州
2024年9月には、カリフォルニア州で、選挙期間中のディープフェイクを規制する法律、ディープフェイクによるヌード画像の作成と拡散を禁止する法律、俳優の権利を守る法律を含む複数のAI関連の法律が成立しました。その中でも重要と思われるのは、「California AI Transparency Act :CAITA」(SB 942)で、2026年1月に発効します。
CAITAの下では、大規模な生成AI提供事業者(毎月のユーザ数が100万人以上のもの)は、①ユーザが生成AIにより生成したすべての生成コンテンツに、生成AIにより生成されたことを示す「明示的な表示」を付けるオプションをユーザに対し提供する、②生成コンテンツに、生成AIで生成されたことを示す「潜在的な表示」(すなわち、人間の目には見えない表示)を付ける、③生成コンテンツ上の明示的および/または潜在的な表示を利用するAI検出ツールを無料で提供することが求められています。
違反1件につき5,000ドルの罰金が科せられます。
他方、先端AI開発に際して、いわゆるキルスイッチの実装を義務づけるなど一定の規制を設ける「The Safe and Secure Innovation for Frontier Artificial Intelligence Models Act」(SB 1047)は、カリフォルニア州知事が署名を拒絶したことから成立しませんでしたが、今後の動向が注目されます。
(5)米国著作権局:著作権登録の可否に関する説明文
また、著作権の登録との関係ではありますが、米国著作権局(U.S. Copyright Office)は、2023年3月16日に、AIを用いて生成されたコンテンツの著作権登録の可否に関する説明文を公表しており 5、その中では、プロンプトのみによって生成されて修正が加えられていないAI作品については、人間の著作物ではなく著作権登録がされない旨が述べられる一方、AI作品に人間が手を加える場合には著作権の発生を認める余地があることを示唆しています。
他方、米国連邦議会図書館議会調査局(Congressional Research Service)が2023年5月11日に修正公表したレポート 6 では、生成AIが生成した著作物の著作権者が誰であるかについて明確な立場はまだ取られておらず、今後の議論が注目されます。
生成AIの法的分析にあたっての視点
生成AIの法的位置づけ
生成AIに関し、現在議論されている問題、特にコンテンツの利活用に関する問題の多くは、大枠では、生成AIの台頭以前から議論されているAIやデータ利活用の問題の範疇にとどまり、まったく新規の問題が生じている状況ではありません。生成AIによる多種多様かつ高品質のコンテンツ生成が可能になったため、各種の問題がより先鋭化した状況と評価できるでしょう。
生成AIの法的な問題の検討に際しては、生成AIをどのように位置づけるかが議論の前提となりますが、「学習済みモデル」と呼ばれるプログラムの一種としての整理が一般的です。学習済みモデルは、機械学習の結果として調整された「学習済みパラメータ(データ)」と、このパラメータを用いて推論等を行う「推論プログラム」で構成されます。生成AIも、機械学習技術を用いて生成されることは変わりませんので、学習の結果創出されるパラメータと、これを実用化するために必要なプログラムを組み合わせたものとして整理できます 7。
もっとも、実務上は、パラメータ単体の活用可能性が限定的であるため、パラメータとプログラムを分けるのではなく、全体として一体化されたプログラムとして学習済みプログラムを整理し、議論することが少なくありません。ただし、プログラム部分が汎用的なソフトウェアの場合には、むしろパラメータの取扱いが重要になるため、パラメータ単体の取扱いを議論することに実益がある場面も考えられます。
本記事および他の関連記事でも、生成AIの中核的な機能を担うプログラムを「生成モデル」と呼び、その利活用に関する議論を整理します。
開発・利用の段階別の論点整理
(1)生成AIサービスの開発〜利用の流れ
生成AIにかぎらず、AIの利活用に関する法的な問題を検討する際には、AIを用いたサービスの中核的な機能を担う学習済みモデルを開発するAI開発・学習段階と、その学習済みモデルを用いてコンテンツを生成したうえで利用する生成・利用段階の2つに分けての検討が、実務上は有益です 8。
その主な理由としては、AI開発・学習段階と生成・利用段階では関与する利害関係者が異なり検討事項が変わり得ることや、たとえば、著作権法の権利制限規定(著作権法30条の4、47条の5)等、それぞれの段階で問題となる規律の適用が異なり得ることが挙げられます。
関連する技術内容によって異なり得るものの、一般的には、おおむね以下の手順を経て、生成AIサービスに用いられる学習済みモデル(生成モデル)が開発され、AI生成物が利用されます。なお、実務では、生成モデルをさらに別のデータセットにより再学習することもありますが(たとえば、LoRA 9 等)、問題状況としては大きく変わりませんので、本記事および他の関連記事では割愛します。
- 大規模な学習用データセット(事前学習用データセット)を用いて「基盤モデル」を開発する
- 事前学習用データセットとは別の再学習用データセット(再学習用データセット)を用いて、基盤モデルの再学習(転移学習やファインチューニング等)をし、個別の適用事例に応じた調整をすることで、生成AIサービス/システムの中核的な機能を担う「生成モデル」を開発する
- ユーザが、生成モデルに対して、プロンプト等の指示やデータ(インプット)を入力して、AI生成物を出力する
- ユーザが、出力されたAI生成物を利用する
以上を図示すると次のとおりです。
生成AIサービスの開発・利用の流れ
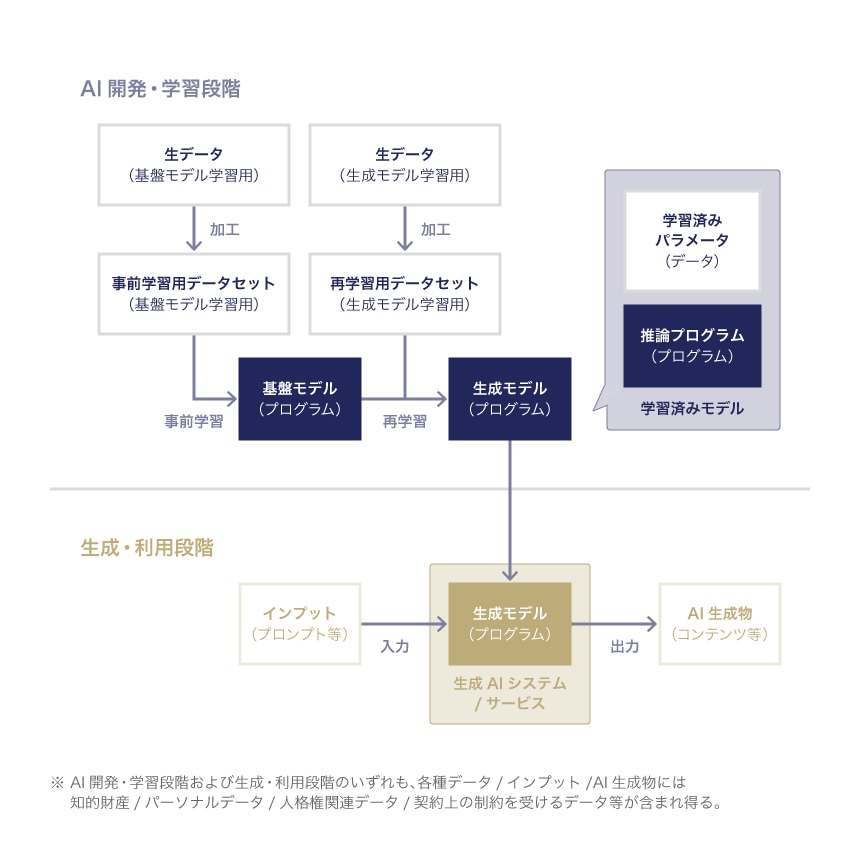
これまでのAI利活用の議論との関係では、議論されるべき検討事項の多くが共通していることは変わりありませんが、AI開発・学習段階で、事前学習と再学習の2以上の多段階の学習が必要となるため、関係当事者が増え、その結果、法的関係が相対的に複雑になる場面が想定されます。
なお、基盤モデルの開発・学習には大規模なデータセットと計算機コストが必要になるため、これを自前で準備する事業者は限定され、多くの企業にとっては、再学習の段階が主に問題になり得るでしょう。ただし、再学習にも一定のコストを要することから、モデルを調整するのではなく、インプットを調整する対応がとられることもあり、そのような技術として、検索拡張生成(RAG:Retrieval Augmented Generation)等が用いられることもあります。
また、AI開発・学習段階と生成・利用段階の構造は、次のとおり、データをプログラムに入力し、新たなデータが出力されるという点で同一であり、その法的問題の多くは、入出力されるデータの取扱い(権利帰属・利用可能性・侵害可能性・適法性等)に帰着します。
- AI開発・学習段階:再学習用データセット⇒学習用プログラム⇒学習済みパラメータ
- 生成・利用段階:インプット⇒生成モデル⇒AI生成物
そのため、いずれの段階でも検討すべき論点自体は変わらないものの、当てはめの段階で各検討事項の重要性などに差異が出ている状況といえるでしょう。
(2)AI開発・学習段階における検討ポイント
AI開発・学習段階では、基盤モデルまたは生成モデルを開発するための学習用データセット(事前学習用データセットおよび再学習用データセット)の取扱いが問題になることが少なくありません。実務上、特に問題になり得るのは、以下のデータを学習に用いる場合です。
- 知的財産に関するデータ(主として著作物データ)
- 個人情報を含むパーソナルデータ
- 人格権関連の権利・利益に関するデータ
- 契約上取扱いが制限されるデータ
なお、このほかにも、生成モデルの開発を外部委託する際や、基盤モデルと生成モデルの開発事業者が異なる場合には、その契約関係の調整も必要になるでしょう。
AI開発・学習段階で検討すべき法的問題の詳細は、下記の記事にて解説します。
(3)生成・利用段階における検討ポイント
生成・利用段階では、生成AIサービスの利用者(ユーザ)と、サービス提供者(AIプロバイダ)のそれぞれについて、異なる検討事項が生じます。
利用者(ユーザ)の観点からの主な検討事項は、生成AIサービスに入力されたインプットの取扱いに加えて、出力されたAI生成物が誰に帰属するのか、そして、いかなる範囲で、他者の権利利益の侵害なく、適法に利用できるのか、という点です。他方、サービス提供者(AIプロバイダ)の観点からの主な検討事項は、生成AIが出力するAI生成物の生成過程等の不確実性に起因したリスクをいかに契約により低減するのか、という点でしょう。
生成・利用段階で検討すべき法的問題の詳細は、下記の記事にて概説します。
-
本記事は、現時点における筆者の個人的な見解を述べるものであり筆者が所属する団体の見解を述べるものではありません。 ↩︎
-
FLOP(Floating-point Operations Per Second)とは、コンピューターが1秒間に実行できる浮動小数点演算の回数で、演算性能の指標の1つです。 ↩︎
-
詳細は、ホワイトハウス「Blueprint for an AI Bill of Rights」(最終閲覧2024年9月17日)参照。 ↩︎
-
Federal Register, Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence, Nov 1, 2023 ↩︎
-
Federal Register, Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence, Mar 16, 2023 ↩︎
-
Congressional Research Service, Generative Artificial Intelligence and Copyright Law, May 11, 2023 ↩︎
-
経済産業省「AI・データの利用に関する契約ガイドライン 1.1版」(令和元年12月)。なお、文化庁著作権課「令和5年度 著作権セミナー AIと著作権」(令和5年6月)27頁等では、学習済みモデルと推論用プログラムが分けて図示される等、経産省ガイドラインとは異なる整理がなされている可能性がありますが、本記事では、経産省ガイドラインの整理を採用しています。 ↩︎
-
各段階の名称は、文化庁著作権課「令和5年度 著作権セミナー AIと著作権」(令和5年6月)によります。 ↩︎
-
LoRA(Low-Ranking Adaptation of Large Language Models)とは、事前学習済みのパラメータを固定したうえで、低ランク行列によりファインチューニングを実施する手法を指します。 ↩︎

西村あさひ法律事務所・外国法共同事業
- IT・情報セキュリティ
- 知的財産権・エンタメ
- 国際取引・海外進出
- 訴訟・争訟
- ベンチャー
